Werte des Testschritts Reconciliation: Row by Row Comparison
Ein Reconciliation-Test bietet einen detaillierten Vergleich zwischen zwei Datensätzen. Er vergleicht jede einzelne Quellzeile mit jeder Zielzeile. Aggregierte Tests sind schneller, während Reconciliation-Tests sehr präzise sind. Je nach Größe Ihrer Datensätze kann der Vergleich jedoch zeit- und ressourcenintensiv sein.
Dieses Kapitel listet alle Row by Row Comparison-Testschrittwerte auf, die Sie zum Erstellen Ihres Reconciliation-Tests benötigen.
Ihre Quelle und Ihr Ziel definieren
Füllen Sie die Testschrittwerte Source und Target aus, um eine Verbindung zu Ihrer Datenquelle und Ihrem Ziel herzustellen. Sie können zwischen den folgenden Datentypen wählen:
Tricentis Data Integrity unterstützt ODBC und JDBC. Je nachdem, was Sie in Ihren Tests verwenden möchten, füllen Sie die folgenden Testschrittwerte aus:
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Connection |
Verwenden Sie dieses Modulattribut, wenn Sie eine der im Connection Manager definierten Verbindungen verwenden möchten. Das Modulattribut Connection ersetzt die Modulattribute DSN, UserID, Password und ConnectionString. Um festzulegen, welche Verbindung Sie in Ihrem Test verwenden möchten, klicken Sie in das Feld Value und wählen Sie eine Verbindung aus dem Aufklappmenü. Beachten Sie, dass Sie die angegebene Verbindung nicht mit dynamischen Ausdrücken wie Buffern oder Testkonfigurationsparametern überschreiben können. |
X |
|
DSN |
Geben Sie die Datenquelle an, die Sie für Ihren Vergleich verwenden möchten. Geben Sie den im ODBC Data Source Administrator angegebenen Data Source Name ein. Nach dem Aufbau einer Verbindung wird dieser Name auch als ConnectionName verwendet. |
X |
|
UserID |
Benutzer der Datenbank, die Sie verwenden möchten. |
X |
|
Password |
Passwort des Benutzers. |
X |
|
Connection String |
Nutzt die definierte Verbindungszeichenfolge anstelle der Modulattribute DSN, UserID und Password. |
X |
|
SQL Statement |
Jedes SQL-Statement. |
|
|
Options - Connection Timeout |
Zeit in Sekunden, nach deren Ablauf Tosca eine aktive Verbindung abbricht. |
X |
|
Options - Command Timeout |
Zeit in Sekunden, nach deren Ablauf Tosca einen aktiven Befehl abbricht. |
X |
|
Options - Byte Array Handling |
Definiert, welche Kodierung Tosca verwenden soll, wenn der Datentyp ein Bytearray ist. |
X |
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Connection String |
JDBC-Verbindungszeichenfolge für den Zugriff auf die Datenbank. Beispiel: jdbc:sqlserver://1.2.3.4:49789;instanceName=SampleInstance;databaseName=TestDB;user=myUser;password=myPassword |
|
|
Class Name |
Klassenname des JDBC-Treibers, den Sie instanziieren möchten. Beispiel: com.mysql.jdbc.Driver |
|
|
Driver Directory |
Verzeichnis des JDBC-Treibers. |
|
|
SQL Statement |
SQL-Statement, das Sie ausführen wollen. |
|
|
Options - Fetch Size |
Legen Sie fest, wie viele Zeilen Tosca DI gleichzeitig abrufen soll, bis alle Quell-/Zielzeilen vorhanden sind. Die Standardanzahl hängt von Ihrem JDBC-Treiber ab. |
X |
Um eine Datei als Quelle oder Ziel zu verwenden, füllen Sie die folgenden Testschrittwerte aus:
Data Integrity unterstützt Avro-Dateien als Quelle oder Ziel.
Einschränkungen
Die Arbeit mit Avro-Dateien hat folgende Einschränkungen:
-
Unterstützte Kompressionscodecs sind GZIP, Snappy und „keine“.
-
Avro-Maps werden nicht unterstützt.
-
Das Überspringen von Zeilen wird nicht unterstützt.
-
Data Integrity unterstützt nur eine Ebene der Verschachtelung für das Ergebnis eines JSONPath. Tiefer verschachtelte Objekte und Arrays werden per Stringify umgewandelt. Um den Zugriff auf tiefer verschachtelte Objekte auszudrücken, verwenden Sie einen separaten JSONPath.
-
Data Integrity unterstützt keine kartesischen Produkte, die vorkommen, wenn zwei JSONPaths Werte aus zwei verschiedenen Arrays zurückgeben.
Mit JSONPaths arbeiten
Mit JSONPaths können Sie eine hierarchische Avro-Datei in ein tabellarisches Format umwandeln. Das Reconciliation-Modul unterstützt nur tabellarische Vergleiche.
Um JSONPaths zu ermitteln und zu testen, empfiehlt Tricentis, die Avro-Datei zunächst in eine JSON-Darstellung zu konvertieren. Um dies zu tun, können Sie ein Online-Tool wie den Avro to json-Konverter verwenden. Dann verwenden Sie die JSON-Ausgabe in einem JSONPath-Tester wie dem JSONPath Online Evaluator.
Sie können eine Datei mit JSONPaths erstellen, um bestimmte Spaltennamen und Transformationslogiken aus Ihrer Avro-Datei auszuwählen. Dies hilft, die Datei zu glätten.

|
In diesem Beispiel verwenden Sie eine Datei mit JSONPaths, um Spaltennamen aus einer Avro-Datei auszuwählen. Zuerst verwenden Sie einen Avro-Dateileser, um den Inhalt Ihrer Datei in das JSON-Format zu konvertieren: Um Spaltennamen auszuwählen, erstellen Sie eine Datei, die JSONPaths im folgenden Format enthält: Kopieren
Der zeilenweise Vergleich kann die Datei nun folgendermaßen lesen: |
Wählen Sie einen der folgenden Avro-Dateitypen:
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Path |
Vollständiger Pfad zu einer Avro-Datei oder einem Ordner, der mehrere Avro-Dateien mit demselben Schema enthält. Sie können Platzhalter * verwenden. Wenn Sie einen Ordner oder Platzhalter verwenden, ordnet Data Integrity die Dateien nach Namen und liest sie von der ersten bis zur letzten. Beispiele: C:\MyAvroFolder\Sample.avro C:\MyAvroFolder C:\MyAvroFolder\Samples*.avro |
|
|
JSONPaths Filename |
Vollständiger Pfad zu einer Datei mit JSONPaths. Dies ermöglicht Tosca die Auswahl von Spaltennamen und Transformationslogik. Die JSONPaths-Datei muss sich im gleichen Bucket/Verzeichnis wie die Datendateien oder in einem Unter-Bucket/Verzeichnis befinden. Wenn sich die Datei in einem Unter-Bucket/Verzeichnis befindet, geben Sie den relativen Pfad zusammen mit dem Dateinamen ein. Wenn Sie diesen Wert leer lassen, verwendet Data Integrity einen Platzhalter * als JSONPath. Es entpackt hierarchische Strukturen eine Ebene tief. Beispielinhalt für JSONPath: Beachten Sie zum Name Folgendes:
|
x |
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Access Key Id |
S3-Zugriffsschlüssel-ID. |
|
|
Bucket Name |
Name des Buckets, der die Datei enthält. Wenn Sie die Datei in einem Unterordner speichern, geben Sie den Pfad im folgenden Format ein: <Bucket-Name>/<Unterordner>. Beispiel: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Vollständiger Name Ihrer Quell-/Zieldatei. Verwenden Sie Platzhalter *, um mehrere Dateien anzugeben. |
|
|
Provider Name |
Name Ihres S3-Anbieters. Sie können einen der folgenden Werte eingeben:
|
|
|
Region |
Die physische Region, in der die Datei gespeichert ist. Beispiele: us-east-1: US-Region, Nord-Virginia oder Pazifischer Nordwesten eu-central-1: Region EU (Frankfurt) ap-southeast-2: Region Asien-Pazifik (Sydney) |
|
|
Secret Access Key |
Geheimer Zugriffsschlüssel. Wenn Sie anonym auf die Datei zugreifen möchten, lassen Sie den Wert leer. |
x |
|
JSONPaths Filename |
Vollständiger Pfad zu einer Datei mit JSONPaths. Dies ermöglicht Tosca die Auswahl von Spaltennamen und Transformationslogik. Die JSONPaths-Datei muss sich im gleichen Bucket/Verzeichnis wie die Datendateien oder in einem Unter-Bucket/Verzeichnis befinden. Wenn sich die Datei in einem Unter-Bucket/Verzeichnis befindet, geben Sie den relativen Pfad zusammen mit dem Dateinamen ein. Wenn Sie diesen Wert leer lassen, verwendet Data Integrity einen Platzhalter * als JSONPath. Es entpackt hierarchische Strukturen eine Ebene tief. Beispielinhalt für JSONPath: Beachten Sie zum Name Folgendes:
|
x |
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Service Account Filepath |
Pfad zur JSON-Datei, die die Anmeldedaten für das Servicekonto enthält. |
|
|
Project Id |
Global eindeutiger Bezeichner des Projekts, auf das Sie zugreifen möchten. |
|
|
Region |
Die physische Region, in der die Datei gespeichert ist. Beispiele: us-east-1: US-Region, Nord-Virginia oder Pazifischer Nordwesten eu-central-1: Region EU (Frankfurt) ap-southeast-2: Region Asien-Pazifik (Sydney) |
|
|
Bucket Name |
Name des Buckets, der die Datei enthält. Wenn Sie die Datei in einem Unterordner speichern, geben Sie den Pfad im folgenden Format ein: <Bucket-Name>/<Unterordner>. Beispiel: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name Ihrer Quell- oder Zieldatei und deren relativer Pfad von der Bucket-Wurzel. |
|
|
JSONPaths Filename |
Vollständiger Pfad zu einer Datei mit JSONPaths. Dies ermöglicht Tosca die Auswahl von Spaltennamen und Transformationslogik. Die JSONPaths-Datei muss sich im gleichen Bucket/Verzeichnis wie die Datendateien oder in einem Unter-Bucket/Verzeichnis befinden. Wenn sich die Datei in einem Unter-Bucket/Verzeichnis befindet, geben Sie den relativen Pfad zusammen mit dem Dateinamen ein. Wenn Sie diesen Wert leer lassen, verwendet Data Integrity einen Platzhalter * als JSONPath. Es entpackt hierarchische Strukturen eine Ebene tief. Beispielinhalt für JSONPath: Beachten Sie zum Name Folgendes:
|
x |
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Account |
Name des Speicherkontos. |
|
|
Key |
Schlüssel des Speicherkontos. |
|
|
SAS Url |
SAS-URL auf Kontoebene oder SAS-URL auf Containerebene. Wenn Sie stattdessen Account und Key verwenden, lassen Sie diesen Wert leer. Beispiel: https://blobname.blob.core.windows.net/?sv=2020-08-04&ss=bfqt&srt=sco&sp=rwdlacupitfx&se=2023-12-10T16:46:02Z&st=2021-12-10T08:46:02Z&spr=https&sig=XXXX |
x |
|
Bucket Name |
Name des Buckets, der die Datei enthält. Wenn Sie die Datei in einem Unterordner speichern, geben Sie den Pfad im folgenden Format ein: <Bucket-Name>/<Unterordner>. Beispiel: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name Ihrer Quell- oder Zieldatei und deren relativer Pfad von der Bucket-Wurzel. |
|
|
JSONPaths Filename |
Vollständiger Pfad zu einer Datei mit JSONPaths. Dies ermöglicht Tosca die Auswahl von Spaltennamen und Transformationslogik. Die JSONPaths-Datei muss sich im gleichen Bucket/Verzeichnis wie die Datendateien oder in einem Unter-Bucket/Verzeichnis befinden. Wenn sich die Datei in einem Unter-Bucket/Verzeichnis befindet, geben Sie den relativen Pfad zusammen mit dem Dateinamen ein. Wenn Sie diesen Wert leer lassen, verwendet Data Integrity einen Platzhalter * als JSONPath. Es entpackt hierarchische Strukturen eine Ebene tief. Beispielinhalt für JSONPath: Beachten Sie zum Name Folgendes:
|
x |
Wenn Sie einen anderen Cloud Service Provider auf Ihrem Windows- oder Linux-Rechner integrieren möchten, müssen Sie Ihre eigene rclone-Konfiguration erstellen. Führen Sie dazu die entsprechende ausführbare Datei aus:
-
rclone_x64_windows.exe config in Windows.
-
rclone_x64_linux config in Linux.
Wenn Sie den Data Integrity Agent unter Windows installieren, befindet sich diese Datei standardmäßig unter C:\Programme\TRICENTIS\Tricentis Tosca Data Integrity Agent\Agent.
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Configuration Filename |
Name der lokalen rclone-Konfigurationsdatei. |
|
|
Remote Name |
Name des Konfigurationsabschnitts aus der Konfigurationsdatei. |
|
|
Bucket Name |
Name des Buckets, der die Datei enthält. Wenn Sie die Datei in einem Unterordner speichern, geben Sie den Pfad im folgenden Format ein: <Bucket-Name>/<Unterordner>. Beispiel: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name Ihrer Quell- oder Zieldatei. |
|
|
JSONPaths Filename |
Vollständiger Pfad zu einer Datei mit JSONPaths. Dies ermöglicht Tosca die Auswahl von Spaltennamen und Transformationslogik. Die JSONPaths-Datei muss sich im gleichen Bucket/Verzeichnis wie die Datendateien oder in einem Unter-Bucket/Verzeichnis befinden. Wenn sich die Datei in einem Unter-Bucket/Verzeichnis befindet, geben Sie den relativen Pfad zusammen mit dem Dateinamen ein. Wenn Sie diesen Wert leer lassen, verwendet Data Integrity einen Platzhalter * als JSONPath. Es entpackt hierarchische Strukturen eine Ebene tief. Beispielinhalt für JSONPath: Beachten Sie zum Name Folgendes:
|
x |
Für weitere Informationen zur Konfiguration von rclone klicken Sie hier.

|
Wenn Sie mit CSV-Dateien arbeiten, verwenden Sie das in RFC 4180 empfohlene Format. Dadurch wird sichergestellt, dass Data Integrity die Dateien ordnungsgemäß verarbeiten kann. |
Wählen Sie einen der folgenden CSV-Dateitypen:
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Filename |
Vollständiger Dateipfad und Dateiname Ihrer Quell- oder Zieldatei. |
|
|
Options - Column Separator |
Zeichen, das Spalten abgrenzt, wenn Sie einen Spaltenbegrenzer in Ihren Tabellen verwenden. |
|
|
Options - Row Separator |
Zeichen, das eine Zeile abgrenzt. Der Standardwert ist \r\n. |
|
|
Options - Skip Lines Starting With |
Zeichen, das Zeilen vom Test ausschließt. Tosca schließt jede Zeile aus, die mit diesem Zeichen beginnt. Sie können mehrere Zeichen definieren. Geben Sie dazu eine durch Semikolon getrennte Liste ein. |
|
|
Options - Encoding |
Datei-Codierungsformat. Geben Sie Default, ASCII, Unicode oder UTF8 ein. Wenn Sie Default eingeben, verwendet Tosca die Codierung Ihres Betriebssystems. |
|
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Hostname |
Name des Hosts, mit dem Sie sich verbinden möchten. Standardmäßig wird Port 22 verwendet. |
|
|
Filename |
Gesamter Dateipfad und Name. Zum Beispiel: /demo/data/Customer/DWH_Extract_Hadoop.txt |
|
|
UserID |
Benutzer, der sich via SSH verbindet. |
|
|
Password |
Passwort des Benutzers. |
|
|
Options - Column Separator |
Geben Sie das Trennzeichen an, wenn Spalten durch ein Trennzeichen getrennt sind. |
|
|
Options - Row Separator |
Zeichen, das eine Zeile abgrenzt. Der Standardwert ist \r\n. |
X |
|
Options - Encoding |
Spezifiziert das Daten-Kodierungsformat. Zulässige Werte sind Default, ASCII, Unicode, UTF32 und UTF8. Das Format Default nutzt die Codierung Ihres Betriebssystems. |
X |
|
Options - Buffer Size |
Anzahl von Bytes, die der Lese-Buffer nutzt um Daten zu holen. Diese Anzahl sollte größer sein als die Anzahl von Bytes per Zeile. Der Standardwert ist 1024. |
X |
|
Options - Skip Lines Starting With |
Zeilen, die mit definierten Werten beginnen, sind von Tests ausgeschlossen. Um mehr als einen Wert zu definieren, geben Sie eine durch Semikolons getrennte Liste ein. |
X |
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Access Key Id |
S3-Zugriffsschlüssel-ID. |
|
|
Bucket Name |
Name des Buckets, der die Datei enthält. Wenn Sie die Datei in einem Unterordner speichern, geben Sie den Pfad im folgenden Format ein: <Bucket-Name>/<Unterordner>. Beispiel: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Vollständiger Name Ihrer Quell-/Zieldatei. Verwenden Sie Platzhalter *, um mehrere Dateien anzugeben. |
|
|
Provider Name |
Name Ihres S3-Anbieters. Sie können einen der folgenden Werte eingeben:
|
|
|
Region |
Die physische Region, in der die Datei gespeichert ist. Beispiele: us-east-1: US-Region, Nord-Virginia oder Pazifischer Nordwesten eu-central-1: Region EU (Frankfurt) ap-southeast-2: Region Asien-Pazifik (Sydney) |
|
|
Secret Access Key |
Geheimer Zugriffsschlüssel. Wenn Sie anonym auf die Datei zugreifen möchten, lassen Sie den Wert leer. |
x |
|
Options - Column Separator |
Zeichen, das Spalten abgrenzt, wenn Sie einen Spaltenbegrenzer in Ihren Tabellen verwenden. |
x |
|
Options - Row Separator |
Zeichen, das eine Zeile abgrenzt. Der Standardwert ist \r\n. |
x |
|
Options - Skip Lines Starting With |
Zeilen, die mit dem angegebenen Wert beginnen, sind von Tests ausgeschlossen. Um mehr als einen Wert zu definieren, geben Sie eine durch Semikolons getrennte Liste ein. |
x |
|
Options - Encoding |
Datei-Codierungsformat. Erlaubte Werte sind Default, ASCII, Unicode und UTF8. Das Format Default nutzt die Codierung Ihres Betriebssystems. |
x |
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Service Account Filepath |
Pfad zur JSON-Datei, die die Anmeldedaten für das Servicekonto enthält. |
|
|
Project Id |
Global eindeutiger Bezeichner des Projekts, auf das Sie zugreifen möchten. |
|
|
Region |
Die physische Region, in der die Datei gespeichert ist. Beispiele: us-east-1: US-Region, Nord-Virginia oder Pazifischer Nordwesten eu-central-1: Region EU (Frankfurt) ap-southeast-2: Region Asien-Pazifik (Sydney) |
|
|
Bucket Name |
Name des Buckets, der die Datei enthält. Wenn Sie die Datei in einem Unterordner speichern, geben Sie den Pfad im folgenden Format ein: <Bucket-Name>/<Unterordner>. Beispiel: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name Ihrer Quell- oder Zieldatei und deren relativer Pfad von der Bucket-Wurzel. |
|
|
Options - Column Separator |
Zeichen, das Spalten abgrenzt, wenn Sie einen Spaltenbegrenzer in Ihren Tabellen verwenden. |
x |
|
Options - Row Separator |
Zeichen, das eine Zeile abgrenzt. Der Standardwert ist \r\n. |
x |
|
Options - Skip Lines Starting With |
Zeilen, die mit dem angegebenen Wert beginnen, sind von Tests ausgeschlossen. Um mehr als einen Wert zu definieren, geben Sie eine durch Semikolons getrennte Liste ein. |
x |
|
Options - Encoding |
Datei-Codierungsformat. Erlaubte Werte sind Default, ASCII, Unicode und UTF8. Das Format Default nutzt die Codierung Ihres Betriebssystems. |
x |
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Account |
Name des Speicherkontos. |
|
|
Key |
Schlüssel des Speicherkontos. |
|
|
SAS Url |
SAS-URL auf Kontoebene oder SAS-URL auf Containerebene. Wenn Sie stattdessen Account und Key verwenden, lassen Sie diesen Wert leer. Beispiel: https://blobname.blob.core.windows.net/?sv=2020-08-04&ss=bfqt&srt=sco&sp=rwdlacupitfx&se=2023-12-10T16:46:02Z&st=2021-12-10T08:46:02Z&spr=https&sig=XXXX |
x |
|
Bucket Name |
Name des Buckets, der die Datei enthält. Wenn Sie die Datei in einem Unterordner speichern, geben Sie den Pfad im folgenden Format ein: <Bucket-Name>/<Unterordner>. Beispiel: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name Ihrer Quell- oder Zieldatei und deren relativer Pfad von der Bucket-Wurzel. |
|
|
Options - Column Separator |
Zeichen, das Spalten abgrenzt, wenn Sie einen Spaltenbegrenzer in Ihren Tabellen verwenden. |
x |
|
Options - Row Separator |
Zeichen, das eine Zeile abgrenzt. Der Standardwert ist \r\n. |
x |
|
Options - Skip Lines Starting With |
Zeilen, die mit dem angegebenen Wert beginnen, sind von Tests ausgeschlossen. Um mehr als einen Wert zu definieren, geben Sie eine durch Semikolons getrennte Liste ein. |
x |
|
Options - Encoding |
Datei-Codierungsformat. Erlaubte Werte sind Default, ASCII, Unicode und UTF8. Das Format Default nutzt die Codierung Ihres Betriebssystems. |
x |
Wenn Sie einen anderen Cloud Service Provider auf Ihrem Windows- oder Linux-Rechner integrieren möchten, müssen Sie Ihre eigene rclone-Konfiguration erstellen. Führen Sie dazu die entsprechende ausführbare Datei aus:
-
rclone_x64_windows.exe config in Windows.
-
rclone_x64_linux config in Linux.
Wenn Sie den Data Integrity Agent unter Windows installieren, befindet sich diese Datei standardmäßig unter C:\Programme\TRICENTIS\Tricentis Tosca Data Integrity Agent\Agent.
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Configuration Filename |
Name der lokalen rclone-Konfigurationsdatei. |
|
|
Remote Name |
Name des Konfigurationsabschnitts aus der Konfigurationsdatei. |
|
|
Bucket Name |
Name des Buckets, der die Datei enthält. Wenn Sie die Datei in einem Unterordner speichern, geben Sie den Pfad im folgenden Format ein: <Bucket-Name>/<Unterordner>. Beispiel: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name Ihrer Quell- oder Zieldatei. |
|
|
Options - Column Separator |
Zeichen, das Spalten abgrenzt, wenn Sie einen Spaltenbegrenzer in Ihren Tabellen verwenden. |
x |
|
Options - Row Separator |
Zeichen, das eine Zeile abgrenzt. Der Standardwert ist \r\n. |
x |
|
Options - Skip Lines Starting With |
Zeilen, die mit dem angegebenen Wert beginnen, sind von Tests ausgeschlossen. Um mehr als einen Wert zu definieren, geben Sie eine durch Semikolons getrennte Liste ein. |
x |
|
Options - Encoding |
Datei-Codierungsformat. Erlaubte Werte sind Default, ASCII, Unicode und UTF8. Das Format Default nutzt die Codierung Ihres Betriebssystems. |
x |
Für weitere Informationen zur Konfiguration von rclone klicken Sie hier.
Tricentis Data Integrity unterstützt Parquet-Dateien als Quelle oder Ziel.
Einschränkungen
Die Arbeit mit Parquet-Dateien hat folgende Einschränkungen:
-
Parquet-Dateien werden tabellarisch gelesen. Hierarchische Strukturen werden in eine Tabellenstruktur umgewandelt.
-
Die unterstützten Kompressionscodecs sind GZIP, Snappy und „keine“.
-
Das Überspringen von Zeilen wird nicht unterstützt.
Wählen Sie einen der folgenden Dateitypen:
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Path |
Vollständiger Pfad zu einer Avro-Datei oder einem Ordner, der mehrere Avro-Dateien mit demselben Schema enthält. Sie können Platzhalter * verwenden. Wenn Sie einen Ordner oder Platzhalter verwenden, ordnet Data Integrity die Dateien nach Namen und liest sie von der ersten bis zur letzten. Beispiele: C:\MyAvroFolder\Sample.avro C:\MyAvroFolder C:\MyAvroFolder\Samples*.avro |
|
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Access Key Id |
S3-Zugriffsschlüssel-ID. |
|
|
Bucket Name |
Name des Buckets, der die Datei enthält. Wenn Sie die Datei in einem Unterordner speichern, geben Sie den Pfad im folgenden Format ein: <Bucket-Name>/<Unterordner>. Beispiel: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Vollständiger Name Ihrer Quell-/Zieldatei. Verwenden Sie Platzhalter *, um mehrere Dateien anzugeben. |
|
|
Provider Name |
Name Ihres S3-Anbieters. Sie können einen der folgenden Werte eingeben:
|
|
|
Region |
Die physische Region, in der die Datei gespeichert ist. Beispiele: us-east-1: US-Region, Nord-Virginia oder Pazifischer Nordwesten eu-central-1: Region EU (Frankfurt) ap-southeast-2: Region Asien-Pazifik (Sydney) |
|
|
Secret Access Key |
Geheimer Zugriffsschlüssel. Wenn Sie anonym auf die Datei zugreifen möchten, lassen Sie den Wert leer. |
x |
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Service Account Filepath |
Pfad zur JSON-Datei, die die Anmeldedaten für das Servicekonto enthält. |
|
|
Project Id |
Global eindeutiger Bezeichner des Projekts, auf das Sie zugreifen möchten. |
|
|
Region |
Die physische Region, in der die Datei gespeichert ist. Beispiele: us-east-1: US-Region, Nord-Virginia oder Pazifischer Nordwesten eu-central-1: Region EU (Frankfurt) ap-southeast-2: Region Asien-Pazifik (Sydney) |
|
|
Bucket Name |
Name des Buckets, der die Datei enthält. Wenn Sie die Datei in einem Unterordner speichern, geben Sie den Pfad im folgenden Format ein: <Bucket-Name>/<Unterordner>. Beispiel: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name Ihrer Quell- oder Zieldatei und deren relativer Pfad von der Bucket-Wurzel. |
|
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Account |
Name des Speicherkontos. |
|
|
Key |
Schlüssel des Speicherkontos. |
|
|
SAS Url |
SAS-URL auf Kontoebene oder SAS-URL auf Containerebene. Wenn Sie stattdessen Account und Key verwenden, lassen Sie diesen Wert leer. Beispiel: https://blobname.blob.core.windows.net/?sv=2020-08-04&ss=bfqt&srt=sco&sp=rwdlacupitfx&se=2023-12-10T16:46:02Z&st=2021-12-10T08:46:02Z&spr=https&sig=XXXX |
x |
|
Bucket Name |
Name des Buckets, der die Datei enthält. Wenn Sie die Datei in einem Unterordner speichern, geben Sie den Pfad im folgenden Format ein: <Bucket-Name>/<Unterordner>. Beispiel: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name Ihrer Quell- oder Zieldatei und deren relativer Pfad von der Bucket-Wurzel. |
|
Wenn Sie einen anderen Cloud Service Provider auf Ihrem Windows- oder Linux-Rechner integrieren möchten, müssen Sie Ihre eigene rclone-Konfiguration erstellen. Führen Sie dazu die entsprechende ausführbare Datei aus:
-
rclone_x64_windows.exe config in Windows.
-
rclone_x64_linux config in Linux.
Wenn Sie den Data Integrity Agent unter Windows installieren, befindet sich diese Datei standardmäßig unter C:\Programme\TRICENTIS\Tricentis Tosca Data Integrity Agent\Agent.
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Configuration Filename |
Name der lokalen rclone-Konfigurationsdatei. |
|
|
Remote Name |
Name des Konfigurationsabschnitts aus der Konfigurationsdatei. |
|
|
Bucket Name |
Name des Buckets, der die Datei enthält. Wenn Sie die Datei in einem Unterordner speichern, geben Sie den Pfad im folgenden Format ein: <Bucket-Name>/<Unterordner>. Beispiel: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name Ihrer Quell- oder Zieldatei. |
|
Für weitere Informationen zur Konfiguration von rclone klicken Sie hier.
Wählen Sie einen der folgenden JSON-Dateitypen:
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Filename |
Vollständiger Dateipfad und Dateiname Ihrer Quell- oder Zieldatei. |
|
|
JSONPaths Filename |
Vollständiger Pfad zu einer Datei mit JSONPaths. Dies ermöglicht Tosca die Auswahl von Spaltennamen und Transformationslogik. Die JSONPaths-Datei muss sich im gleichen Bucket/Verzeichnis wie die Datendateien oder in einem Unter-Bucket/Verzeichnis befinden. Wenn sich die Datei in einem Unter-Bucket/Verzeichnis befindet, geben Sie den relativen Pfad zusammen mit dem Dateinamen ein. Wenn Sie diesen Wert leer lassen, verwendet Data Integrity einen Platzhalter * als JSONPath. Es entpackt hierarchische Strukturen eine Ebene tief. Beispielinhalt für JSONPath: Beachten Sie zum Name Folgendes:
|
x |
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Access Key Id |
S3-Zugriffsschlüssel-ID. |
|
|
Bucket Name |
Name des Buckets, der die Datei enthält. Wenn Sie die Datei in einem Unterordner speichern, geben Sie den Pfad im folgenden Format ein: <Bucket-Name>/<Unterordner>. Beispiel: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Vollständiger Name Ihrer Quell-/Zieldatei. Verwenden Sie Platzhalter *, um mehrere Dateien anzugeben. |
|
|
Provider Name |
Name Ihres S3-Anbieters. Sie können einen der folgenden Werte eingeben:
|
|
|
Region |
Die physische Region, in der die Datei gespeichert ist. Beispiele: us-east-1: US-Region, Nord-Virginia oder Pazifischer Nordwesten eu-central-1: Region EU (Frankfurt) ap-southeast-2: Region Asien-Pazifik (Sydney) |
|
|
Secret Access Key |
Geheimer Zugriffsschlüssel. Wenn Sie anonym auf die Datei zugreifen möchten, lassen Sie den Wert leer. |
x |
|
JSONPaths Filename |
Vollständiger Pfad zu einer Datei mit JSONPaths. Dies ermöglicht Tosca die Auswahl von Spaltennamen und Transformationslogik. Die JSONPaths-Datei muss sich im gleichen Bucket/Verzeichnis wie die Datendateien oder in einem Unter-Bucket/Verzeichnis befinden. Wenn sich die Datei in einem Unter-Bucket/Verzeichnis befindet, geben Sie den relativen Pfad zusammen mit dem Dateinamen ein. Wenn Sie diesen Wert leer lassen, verwendet Data Integrity einen Platzhalter * als JSONPath. Es entpackt hierarchische Strukturen eine Ebene tief. Beispielinhalt für JSONPath: Beachten Sie zum Name Folgendes:
|
x |
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Service Account Filepath |
Pfad zur JSON-Datei, die die Anmeldedaten für das Servicekonto enthält. |
|
|
Project Id |
Global eindeutiger Bezeichner des Projekts, auf das Sie zugreifen möchten. |
|
|
Region |
Die physische Region, in der die Datei gespeichert ist. Beispiele: us-east-1: US-Region, Nord-Virginia oder Pazifischer Nordwesten eu-central-1: Region EU (Frankfurt) ap-southeast-2: Region Asien-Pazifik (Sydney) |
|
|
Bucket Name |
Name des Buckets, der die Datei enthält. Wenn Sie die Datei in einem Unterordner speichern, geben Sie den Pfad im folgenden Format ein: <Bucket-Name>/<Unterordner>. Beispiel: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name Ihrer Quell- oder Zieldatei und deren relativer Pfad von der Bucket-Wurzel. |
|
|
JSONPaths Filename |
Vollständiger Pfad zu einer Datei mit JSONPaths. Dies ermöglicht Tosca die Auswahl von Spaltennamen und Transformationslogik. Die JSONPaths-Datei muss sich im gleichen Bucket/Verzeichnis wie die Datendateien oder in einem Unter-Bucket/Verzeichnis befinden. Wenn sich die Datei in einem Unter-Bucket/Verzeichnis befindet, geben Sie den relativen Pfad zusammen mit dem Dateinamen ein. Wenn Sie diesen Wert leer lassen, verwendet Data Integrity einen Platzhalter * als JSONPath. Es entpackt hierarchische Strukturen eine Ebene tief. Beispielinhalt für JSONPath: Beachten Sie zum Name Folgendes:
|
x |
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Account |
Name des Speicherkontos. |
|
|
Key |
Schlüssel des Speicherkontos. |
|
|
SAS Url |
SAS-URL auf Kontoebene oder SAS-URL auf Containerebene. Wenn Sie stattdessen Account und Key verwenden, lassen Sie diesen Wert leer. Beispiel: https://blobname.blob.core.windows.net/?sv=2020-08-04&ss=bfqt&srt=sco&sp=rwdlacupitfx&se=2023-12-10T16:46:02Z&st=2021-12-10T08:46:02Z&spr=https&sig=XXXX |
x |
|
Bucket Name |
Name des Buckets, der die Datei enthält. Wenn Sie die Datei in einem Unterordner speichern, geben Sie den Pfad im folgenden Format ein: <Bucket-Name>/<Unterordner>. Beispiel: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name Ihrer Quell- oder Zieldatei und deren relativer Pfad von der Bucket-Wurzel. |
|
|
JSONPaths Filename |
Vollständiger Pfad zu einer Datei mit JSONPaths. Dies ermöglicht Tosca die Auswahl von Spaltennamen und Transformationslogik. Die JSONPaths-Datei muss sich im gleichen Bucket/Verzeichnis wie die Datendateien oder in einem Unter-Bucket/Verzeichnis befinden. Wenn sich die Datei in einem Unter-Bucket/Verzeichnis befindet, geben Sie den relativen Pfad zusammen mit dem Dateinamen ein. Wenn Sie diesen Wert leer lassen, verwendet Data Integrity einen Platzhalter * als JSONPath. Es entpackt hierarchische Strukturen eine Ebene tief. Beispielinhalt für JSONPath: Beachten Sie zum Name Folgendes:
|
x |
Wenn Sie einen anderen Cloud Service Provider auf Ihrem Windows- oder Linux-Rechner integrieren möchten, müssen Sie Ihre eigene rclone-Konfiguration erstellen. Führen Sie dazu die entsprechende ausführbare Datei aus:
-
rclone_x64_windows.exe config in Windows.
-
rclone_x64_linux config in Linux.
Wenn Sie den Data Integrity Agent unter Windows installieren, befindet sich diese Datei standardmäßig unter C:\Programme\TRICENTIS\Tricentis Tosca Data Integrity Agent\Agent.
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Configuration Filename |
Name der lokalen rclone-Konfigurationsdatei. |
|
|
Remote Name |
Name des Konfigurationsabschnitts aus der Konfigurationsdatei. |
|
|
Bucket Name |
Name des Buckets, der die Datei enthält. Wenn Sie die Datei in einem Unterordner speichern, geben Sie den Pfad im folgenden Format ein: <Bucket-Name>/<Unterordner>. Beispiel: MyBucketName/MyFolder/AnotherFolder |
|
|
Filename |
Name Ihrer Quell- oder Zieldatei. |
|
|
JSONPaths Filename |
Vollständiger Pfad zu einer Datei mit JSONPaths. Dies ermöglicht Tosca die Auswahl von Spaltennamen und Transformationslogik. Die JSONPaths-Datei muss sich im gleichen Bucket/Verzeichnis wie die Datendateien oder in einem Unter-Bucket/Verzeichnis befinden. Wenn sich die Datei in einem Unter-Bucket/Verzeichnis befindet, geben Sie den relativen Pfad zusammen mit dem Dateinamen ein. Wenn Sie diesen Wert leer lassen, verwendet Data Integrity einen Platzhalter * als JSONPath. Es entpackt hierarchische Strukturen eine Ebene tief. Beispielinhalt für JSONPath: Beachten Sie zum Name Folgendes:
|
x |
Für weitere Informationen zur Konfiguration von rclone klicken Sie hier.
Um OLAP zu verwenden, füllen Sie die folgenden Testschrittwerte aus:
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
SSAS |
Verbinden Sie sich mit SQL Server Analysis Services. |
|
|
SSAS - Connection string |
Verbindungszeichenfolge für SSAS. |
|
|
SSAS - Query |
Abfrage zum Abrufen von Daten für einen Vergleich. |
|
|
SSAS - Options - Connect Timeout |
Zeit in Sekunden, nach der Tosca DI eine aktive Verbindung abbricht. Der Standardwert ist 30 Sekunden. |
X |
|
SSAS - Options - Command Timeout |
Zeit in Sekunden, nach der Tosca DI einen aktiven Befehl abbricht. Der Standardwert ist 180 Sekunden. |
X |
Tricentis Data Integrity unterstützt benutzerdefinierte Datenquellen. Klicken Sie hier für Informationen zur Integration Ihres benutzerdefinierten Datenquellenlesers.
Sobald Sie dies getan haben, füllen Sie die folgenden Testschrittwerte aus:
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Class Attribute Name |
Geben Sie im Feld Value den Namen Ihres benutzerdefinierten Datenquellenlesers ein. Der Name wird im ClassAttributeName Ihrer Datenquellenschnittstelle deklariert. Beispiel: CustomCSVReader |
|
|
Parameters - Key |
Geben Sie das Schlüssel-Wert-Paar an, um Informationen an Ihren benutzerdefinierten Implementierungscode zu übergeben:
Beispiel: Name FilePath, Wert D:\TestFile.csv Wenn Sie mit COBOL-Dateien arbeiten, müssen Sie bestimmte Parameter verwenden (siehe Kapitel "Tests mit COBOL-Dateien ausführen"). |
|
|
|
In diesem Beispiel möchten Sie Daten aus zwei CSV-Dateien vergleichen. Sie verwenden dazu einen benutzerdefinierten CSV-Dateileser (siehe unser Codebeispiel). Sie führen die folgenden Schritte aus:
Row by Row Comparison mit benutzerdefiniertem Datenquellenleser Sie können nun Ihren Testfall ausführen. |

Zusätzliche Quell- und Zielkonfigurationen
Es gibt zusätzliche Parameter in den Testschrittwerten Source und Target, mit denen Sie definieren können, wie Zeilen, Spalten und Zellen während des Reconciliation-Tests zu behandeln sind.
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Skip first #n rows |
Definieren Sie die Anzahl der Zeilen, die ignoriert werden sollen. Das Überspringen beginnt am Anfang der Datenquelle. |
X |
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
1st Row Contains Column Names |
Spezifiziert ob die erste Zeile der Datenquelle die Spaltennamen enthält. Der Standardwert ist True. |
X |
|
RemapColumn Names |
Ordnen Sie die Spaltennamen über eine Datei neu zu. Geben Sie den vollständigen Dateipfad zu einer Text- oder CSV-Datei mit den Spaltenzuordnungen an. Die Datei muss mit der Kopfzeile Aktueller Spaltenname;Zugeordneter Spaltenname, gefolgt von einer Zeile für jede Spalte, die Sie umbenennen möchten, beginnen. Beispiel: Aktueller Spaltenname;Zugeordneter Spaltenname Name1;Vorname Name2;Nachname |
X |
|
Remap Column Names - Current Name |
Ordnen Sie die Spaltennamen manuell neu zu. Geben Sie in der Spalte Name den Namen der Spalte an, die Sie umbenennen möchten. Geben Sie in der Spalte Value den neuen Namen an. |
X |
|
Tosca verwendet dieses Gebietsschema, um das Format der Zahlenwerte, hauptsächlich Dezimal- und Tausendertrennzeichen, der Spalten zu bestimmen, die unter Tolerances definiert sind. |
X |
Cell settings enthält zwei Optionen:
-
All Columns - Option wendet eine Aktion auf alle Spalten an.
-
Single Columns - <Name> wendet eine Aktion auf eine bestimmte Spalte an. Um eine Spalte anzugeben, ersetzen Sie <Name> durch den Spaltennamen.
Sie können die folgenden Werte anwenden:
|
Wert |
Beschreibung |
|---|---|
|
Trim |
Entfernt alle führenden und nachfolgenden Leerräume. Standardeinstellung: HeaderAndData |
|
Trim[<character>] |
Entfernt alle führenden und abschließenden Vorkommen des angegebenen Zeichens. Standardeinstellung: HeaderAndData Ersetzen Sie <character> durch das zu entfernende Zeichen. Um ein " zu entfernen, geben Sie das " vier Mal ein, z. B. Trim[""""]. |
|
TrimStart |
Entfernt alle führenden Leerräume. Standardeinstellung: HeaderAndData |
|
TrimStart[<character>] |
Entfernt alle führenden Vorkommen des angegebenen Zeichens. Standardeinstellung: HeaderAndData Ersetzen Sie <character> durch das zu entfernende Zeichen. Um ein " zu entfernen, geben Sie das " vier Mal ein, z. B. TrimStart[""""]. |
|
TrimEnd |
Entfernt alle nachfolgenden Leerzeichen. Standardeinstellung: HeaderAndData |
|
TrimEnd[<character>] |
Entfernt alle abschließenden Vorkommen des angegebenen Zeichens. Standardeinstellung: HeaderAndData Ersetzen Sie <character> durch das zu entfernende Zeichen. Um ein " zu entfernen, geben Sie das " vier Mal ein, z. B. TrimEnd[""""]. |
|
Replace[<string>][<string>] |
Ersetzt alle Vorkommen der ersten durch die zweite Zeichenfolge. Standardeinstellung: Data |
|
ReplaceRegex [<search regex>][<replace string>] |
Ersetzt Zeichenfolgen durch reguläre Ausdrücke. Sie können Sonderzeichen und Unicode-Symbole ersetzen oder Erfassungsgruppen verwenden. Wenn Sie geschwungene Klammern {} verwenden möchten, müssen Sie diese mit doppelten Anführungszeichen "" maskieren. Standardeinstellung: Data |
|
Substring[<start index>] |
Extrahiert einen Teil einer längeren Zeichenfolge. Das Extrahieren beginnt an der definierten Position start index und wird bis zum Ende der Zeichenfolge ausgeführt. Standardeinstellung: Data Beispiel: Substring[9] mit Eingabe Project Manager gibt Manager zurück. |
|
Substring[<start index>][<length>] |
Extrahiert einen Teil einer längeren Zeichenfolge. Das Extrahieren beginnt an der definierten Position start index und enthält die Anzahl der in length angegebenen Zeichen. Standardeinstellung: Data Beispiel: Substring[9][3] mit Eingabe Project Manager gibt Man zurück. |
|
Right[<length>] |
Extrahiert einen Teil einer längeren Zeichenfolge. Das Extrahieren wird vom Ende der Zeichenfolge in Richtung des Anfangs ausgeführt und enthält die Anzahl der in length angegebenen Zeichen. Standardeinstellung: Data Beispiel: Right[7] mit Eingabe Project Manager gibt Manager zurück. |
|
Lowercase |
Konvertiert die Zeichenfolge unter Verwendung des aktuell aktiven Gebietsschemas in Kleinbuchstaben. Standardeinstellung: Data Beispiel: Lowercase mit Engabe Project Manager gibt project manager zurück. |
|
Lowercase[Culture:<culture name>] |
Konvertiert die gesamte Zeichenfolge in Kleinbuchstaben. Lowercase[Culture:<culture name>] verwendet den gegebenen Kulturnamen, um ein neues Gebietsschema zu erstellen. Standardeinstellung: Data Beispiel: Lowercase[Culture:zh-Hans] verwendet die Kulturinformationen von "Chinese(simplified)", um die Groß- in Kleinbuchstaben zu konvertieren. |
|
Uppercase |
Konvertiert die Zeichenfolge unter Verwendung des aktuell aktiven Gebietsschemas in Großbuchstaben. Standardeinstellung: Data Beispiel: Uppercase mit Eingabe Project Manager gibt PROJECT MANAGER zurück. |
|
Uppercase[Culture:<culture name>] |
Konvertiert die gesamte Zeichenfolge in Großbuchstaben. Uppercase[Culture:<culture name>] verwendet den gegebenen Kulturnamen, um ein neues Gebietsschema zu erstellen. Standardeinstellung: Data Beispiel: Lowercase[Culture:en-us] verwendet die Kulturinformationen von "English - United States", um die Klein- in Großbuchstaben zu konvertieren. |
|
Trim double quotes |
Entfernt führende und nachfolgende doppelte Anführungszeichen. Beispiel: Trim double quotes mit der Eingabe """Projektmanager""" gibt Projektmanager zurück. |
Um die Standardeinstellung einer Aktion zu ändern, fügen Sie einen Parameter Scope hinzu:
-
Um die Aktion nur auf die Kopfzeile anzuwenden, fügen Sie den Parameter [Scope:Header] hinzu.
-
Um die Aktion auf alle Datenzeilen, jedoch nicht auf die Kopfzeile anzuwenden, fügen Sie den Parameter [Scope:Data] hinzu.
-
Um die Aktion auf die Kopfzeile und alle Datenzeilen anzuwenden, fügen Sie den Parameter [Scope:HeaderAndData] hinzu.
|
|
Dieses Beispiel zeigt, wie alle Instanzen der Zeichenfolge CustomerDataAustria durch die Zeichenfolge CustomerDataUSA ersetzt werden. Wenden Sie diese Änderung auf den Header und alle Datenzeilen an. Definieren Sie hierzu die folgende Aktion: Replace[<CustomerDataAustria>][<CustomerDataUSA>][Scope:HeaderAndData] |
Ihren Row Key definieren
Der Row by Row Comparison-Algorithmus verwendet den Row Key als eindeutigen Bezeichner, um Zeilen zu vergleichen.
|
Wert |
Beschreibung |
|---|---|
|
Row Key |
Geben Sie den Row Key auf eine der folgenden Arten an:
Der oder die Spaltennamen, die Sie im Row Key angeben, müssen genau dem/denen in der Tabelle entsprechen. Dies umfasst auch Großschreibung und Leerzeichen. |
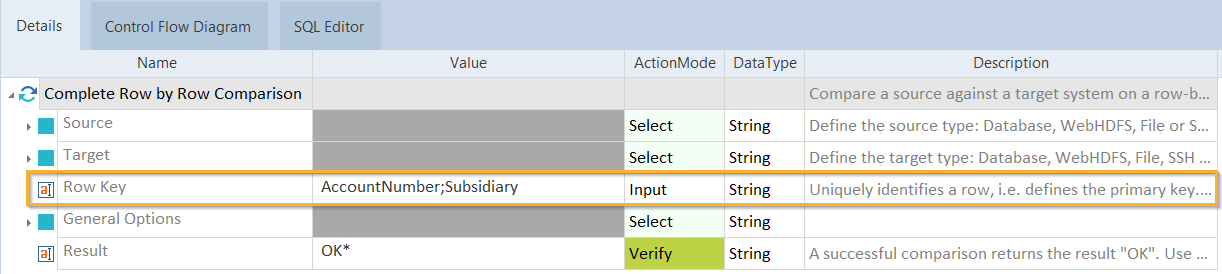
Row Key mit zwei Spaltennamen
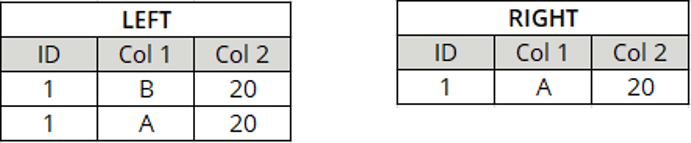
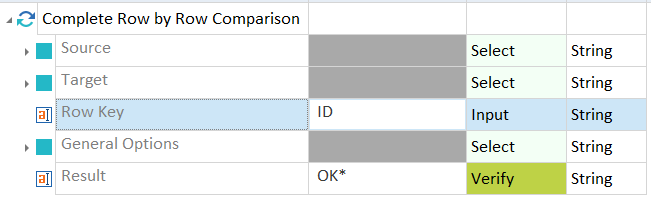

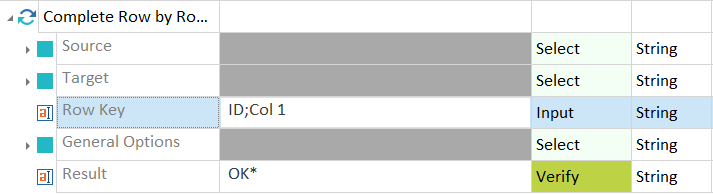

Allgemeine Optionen definieren
Füllen Sie die General Options-Testschrittwerte aus, um allgemeine Testparameter zu definieren.
Sie können die folgenden Testschrittwerte verwenden:
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Max Errors |
Geben Sie die maximale Anzahl von Fehlern an, bevor Data Integrity die Ausführung abbricht. Der Standardwert ist 100. |
X |
|
Columns to Exclude |
Durch Semikolons getrennte Liste von Spalten, die vom Vergleich ausgenommen werden. |
X |
|
Case Sensitive Column Names |
Falls auf True gesetzt, muss beim Spaltenabgleich von Quelle zu Ziel auf Groß- und Kleinschreibung geachtet werden. Zum Beispiel: ID ist nicht das Gleiche wie id. |
X |
|
Skip Rowcount |
Data Integrity führt standardmäßig eine Zeilenzählung durch, bevor es berechnet, wie lange der Vergleich dauern wird. Sie können die Zeilenzählung überspringen, um Zeit zu sparen. Setzen Sie dazu dieses Attribut auf True. Standardwert: False |
X |
|
Ermöglicht den Vergleich einer leeren Quelle und/oder eines leeren Ziels, ohne einen Fehler auszulösen. Dies bedeutet, dass der Test durchläuft und einen Report erstellt. Dies ist nützlich, wenn Sie erwarten, dass die Quelle oder das Ziel leer ist und der Test bestanden werden sollte. Setzen Sie dazu dieses Attribut auf True. Standardwert: False Hinweis: Überlegen Sie, ob Sie nicht zugeordnete Zielzeilen mit Export Unmatched Target Rows exportieren möchten. Nähere Informationen finden Sie in den folgenden Tabellen. |
X |
Die folgende Tabelle zeigt, wie der Vergleich einer leeren Datenquelle erfolgt, wenn Sie Allow Empty Comparison auf True setzen.
|
Source |
Target |
Export Unmatched Target Rows |
Erwartetes Testergebnis |
|---|---|---|---|
|
Leer |
Leer |
True |
Bestanden: Test läuft durch. |
|
Leer |
Leer |
False |
Bestanden: Test läuft durch. |
|
Leer |
NICHT leer |
True |
Fehlgeschlagen: Test läuft durch, zeigt Unterschiede an. |
|
Leer |
NICHT leer |
False |
Bestanden: Test läuft durch, zeigt an, dass keine Unterschiede gefunden wurden. |
|
NICHT leer |
Leer |
True |
Fehlgeschlagen: Test läuft durch, zeigt Unterschiede an. |
|
NICHT leer |
Leer |
False |
Fehlgeschlagen: Test läuft durch, zeigt Unterschiede an. |
Die folgende Tabelle zeigt, wie der Vergleich einer leeren Datenquelle abläuft, wenn Sie Allow Empty Comparison auf False setzen.
|
Source |
Target |
Export Unmatched Target Rows |
Erwartetes Testergebnis |
|---|---|---|---|
|
Leer |
Leer |
True |
Löst einen Fehler aus, erstellt keinen Report. |
|
Leer |
Leer |
False |
Löst einen Fehler aus, erstellt keinen Report. |
|
Leer |
NICHT leer |
True |
Fehlgeschlagen: Test läuft durch, zeigt Unterschiede an. |
|
Leer |
NICHT leer |
False |
Löst einen Fehler aus, erstellt keinen Report. |
|
NICHT leer |
Leer |
True |
Fehlgeschlagen: Test läuft durch, zeigt Unterschiede an. |
|
NICHT leer |
Leer |
False |
Fehlgeschlagen: Test läuft durch, zeigt Unterschiede an. |
Vergleichsreports ermöglichen es Ihnen, detaillierte Reports zu speichern. Tosca speichert die Daten in einer lokalen Datenbankdatei, die Sie mit dem Data Integrity Report Viewer anzeigen können.
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Report Path |
Geben Sie den vollständigen Pfad und Dateiname für Ihren Vergleichsreport oder nur einen Dateipfad an. Wenn Sie nur einen Dateipfad angeben, generiert Data Integrity einen Standarddateinamen im folgenden Format: TestResultReport_yyyyMMdd-HHmmss. Wenn Sie beispielsweise den Dateipfad C:\temp oder C:\temp\ angeben, generiert Data Integrity die Reportdatei C:\temp\TestResultReport_yyyyMMdd-HHmmss. |
X |
|
Export Unmatched Target Rows |
Wählen Sie eine der folgenden Exportoptionen:
Wenn Ihr Ziel viele nicht zugeordnete Zeilen enthält, kann dies die Leistung beeinträchtigen, da alle Zeilen exportiert werden müssen. |
X |
|
Export Matched Data |
Wählen Sie eine der folgenden Exportoptionen:
Tricentis rät davon ab, alle abgeglichenen Daten zu protokollieren, da sich dies negativ auf die Leistung auswirkt. |
X |
Das Ziel der Row by Row Comparison ist es, zu bestätigen, dass die Daten von Quellzeile und Zielzeile übereinstimmen. Wenn die Zeilen nicht in allen Spalten übereinstimmen, betrachtet Tricentis Data Integrity sie als Konflikt.
Sie können jedoch mithilfe von Toleranzen festlegen, welche Differenz zwischen den verglichenen Werten zulässig ist. Auf diese Weise kann Data Integrity auch bei geringen Unterschieden zwischen Quell- und Zielwert diese als Übereinstimmung betrachten.
Klicken Sie hier für weitere Informationen zu Toleranzen.
|
Wert |
Beschreibung |
|---|---|
|
Tolerances |
Geben Sie einen der folgenden Werte an:
Wenn Sie zwei Werte verwenden, um einen Toleranzbereich anzugeben, trennen Sie diese mit einem Semikolon. Beispielwert: -5;+5 |
Ergebnis überprüfen
Mit dem Testschrittwert Result können Sie das Ergebnis des Vergleichs überprüfen. Geben Sie dazu einen der folgenden Werte in die Spalte Value ein:
-
Um auf einen erfolgreichen Vergleich zu überprüfen, geben Sie den Wert OK ein.
-
Um auf ein erwartetes Ergebnis zu überprüfen, verwenden Sie den Ergebnistext aus der Loginfo, nachdem Sie Ihren Testfall ausgeführt und angepasst haben.

Auf erwartetes Ergebnis überprüfen