PDFファイルからリンクを抽出する
PDF Engine 3.0 の Extract Links モジュールを使用すると、スキャンすることなくPDFファイル内のリンクを簡単にバッファリングできます。Toscaがリンクを自動的に検出し、取得します。
リンクをバッファリングする
PDFファイル内のリンクをバッファリングするには、以下の手順に従ってください。
-
Extract Links モジュールからテストケースを作成します。
-
「 PDF File 」にファイル名および拡張子を含めたPDFのフルパスを指定します。
-
必要に応じて、バッファリングしたいリンクを指定します。PDFファイルに複数のリンクが含まれている場合、Toscaはそれらをすべて配列としてバッファリングします。デフォルトでは、テストステップは配列内の最初のリンクを使用します。
-
特定のリンクを使用するには、「 Indexes 」にそのリンクの配列内での位置を指定します。たとえば、 3 番目のリンクを使用したい場合は、「3」と入力してください。
-
複数のリンクを使用するには、「 Indexes 」にそれらのリンクの配列内での位置を指定します。たとえば、最初のリンク、2番目のリンク、3番目のリンクが必要な場合は、「 1-3 」と入力します。
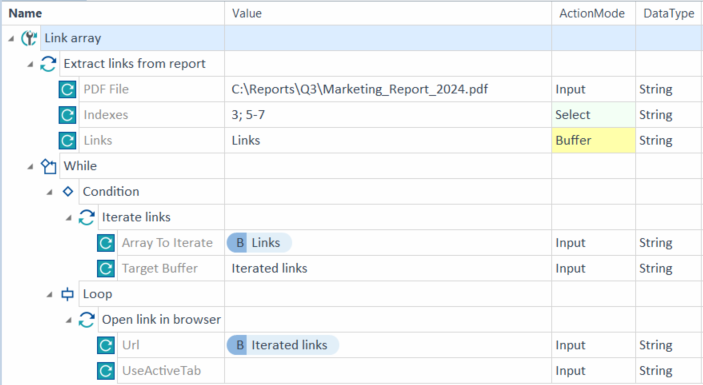
複数のリンクをバッファリングする場合は、続くテストステップでバッファリングされた配列を反復処理する必要があります。下の例をご覧ください。
-
-
「 Links 」を通してバッファを設定します。バッファに名前を付け、「ActionMode」で「 Buffer 」を選択します。

|
この例では、PDFから複数のリンクを抽出します。3番目、5番目、6番目、7番目のリンクのみをバッファリングしたいとします。
抽出されたリンクの配列を反復処理する |