PDF モジュール
標準サブセット内の Engines->;Pdf フォルダには、 PDF Engine 3.0 の特定のタスクを実行するためのモジュールが含まれています。
PDF 1:1 Compare
PDF 1:1 Compare モジュールを使用すると、2つのPDFファイルを比較できます。
PDF Engine 3.0 は、2つのファイルを視覚的に比較します。
-
2つのファイルの類似度が一定のパーセンテージ以上であれば、テストケースは成功します。
-
2つのファイルの類似度が期待値以下の場合、テストケースは失敗します。
モジュールには以下のModuleAttributesがあります。
|
ModuleAttribute |
説明 |
|---|---|
|
参照ファイル |
ファイル名および拡張子を含む、最初のPDFファイルへのフルパス。 |
|
Reference File Password |
最初のPDFファイルを開くためのパスワード。 |
|
Target File(s) |
参照ファイルと比較するファイルを指定します。 単一のターゲットファイルと比較するには、以下のいずれかの方法を選択します。
複数のターゲットファイルと比較するには、以下のいずれかの方法を選択します。
|
|
Target File Password(s) |
ターゲットファイルを復号するためのパスワード。複数のパスワードを指定する場合は、セミコロン(;)で区切って入力します。 さらに、以下のことに注意してください。
|
|
精度 [%] |
2つのファイルの最小類似度をパーセントで指定します。 |
|
Comparison Type |
実行する比較のタイプを指定します。
加えて、Toscaに空白文字を無視するよう指示することもできます。これを行うには「 Ignore whitespace in text-only comparison 」の設定を使用してください。 |
|
Excluded Pages |
必要に応じて、比較から除外したいページを指定します。 ページ範囲を指定するには、ハイフン(-)を使用します。複数のページあるいはページ範囲を指定するには、セミコロン(;)を使用します。 |
|
除外領域 |
オプションで、比較から除外したいPDFファイルの領域を指定します。以下のModuleAttributesは各除外領域に適用されます。
|
|
除外テキスト |
オプションで、比較から除外したいテキストのパターンを指定します。必要に応じて、正規表現を使用して、一意のパターンを指定することができます。正規表現の検証には Regular Expressions 101 の使用を推奨します。 以下のModuleAttributesは、各除外パターンに適用されます。
|

|
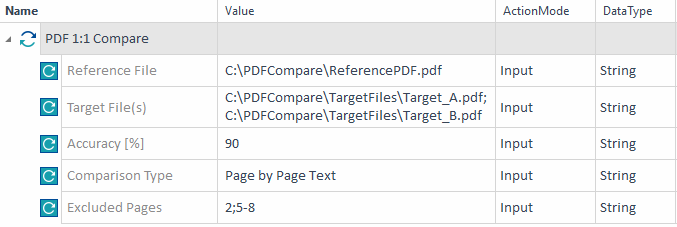
この例では、 ReferencePDF.pdf ファイルのテキスト内容を、 Target_A.pdf ファイルと Target_B.pdf ファイルと比較 しています。 ファイルは少なくとも 90 パーセント以上類似しているはずです。 ページ2とページ5から8を比較から除外します。
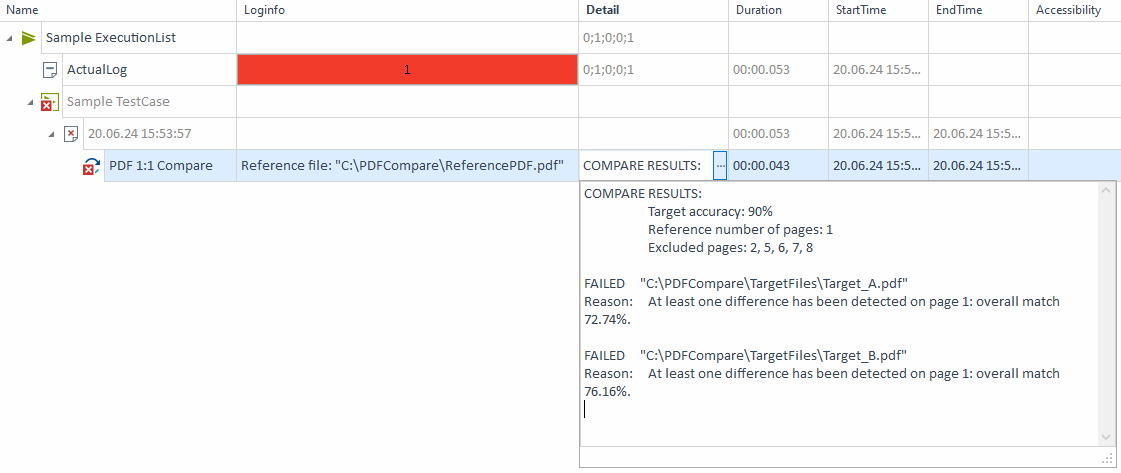
2つのPDFファイルを比較 比較結果は、ファイルが指定した最小類似度を持たないことを示します。 その結果、テストケースは失敗します。
PDF比較の失敗 |
|
|
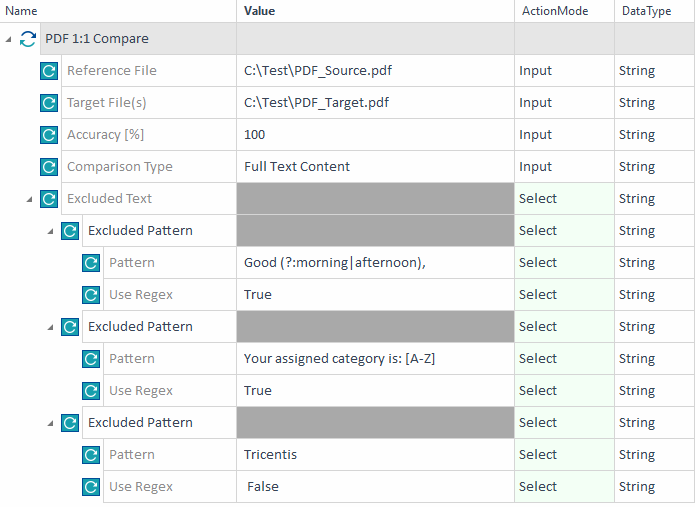
この例では、 2つのPDFファイル間のテキストのみを比較し 、100%の類似性を期待しています。さらに、3つの異なるテキストパターンを比較から除外します。
|
CheckPDF for Broken Links
Check PDF for Broken Links モジュールを使用すると、PDFファイル内のリンクがクライアントエラー応答(400~499)あるいはサーバーエラー応答(500~599)を返すかどうかチェックできます。インスタンスとして、これは、文書内のリンク切れの有無を確認するのに役立ちます。
モジュールには以下のModuleAttributesがあります。
|
ModuleAttribute |
説明 |
|---|---|
|
PDFファイル |
確認することを希望のPDFファイルへの完全なパス。 例: C:\MyReports\YearlyReport.pdf |
|
エラーを無視 |
テストで無視したいエラーコード。 たとえば、 403 を入力すると「Forbidden」応答を返すすべてのリンクを無視することができます。 |
|
|
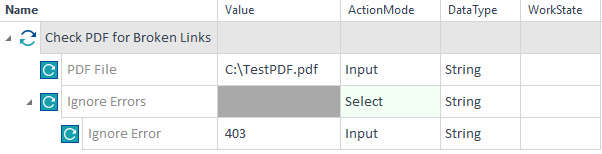
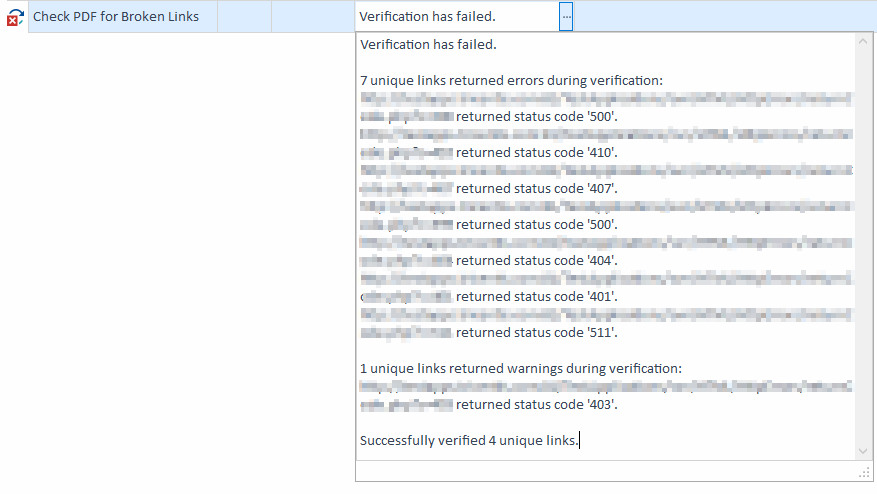
このテストケース例は、 C:\TestPDF.pdf にあるPDFファイルにリンク切れがないか調べます。403 エラーを除くすべてのエラータイプをチェックします。
例 - エラー応答のチェック ウィンドウが見つかると、このウェブページ内のすべてのリンクのエラー応答を検証します:
Tricentis Toscaのリンク検証例 |
Barcode Reader
Barcode Reader モジュールを使用すると、PDFファイル内の以下のバーコードおよびQRコードの値を検証したりバッファしたりすることができます。
-
バーコード用: Code39 Code93 Code128 EAN-8,EAN-13 UPC-A, UPC-E, ITF, Industrial2of5 Inverted2of5 IATA, Add2 Add5 Matrix2of5 Datalogic2of5 Codabar, BCD Matrix
-
QRコード用:QR, Micro QR, Data Matrix, PDF417, Aztec.
モジュールには、以下のモジュール属性があります。
|
ModuleAttribute |
説明 |
|---|---|
|
PDFファイル |
PDFファイルへの絶対パス。 |
|
バーコード - タイプ |
スキャンしたいバーコードの種類を指定します。
|
|
バーコード - ページ |
オプションで、バーコードまたはQRコードをチェックするページを指定します。これを空白のままにすると、Tricentis Toscaはすべてのページをチェックします。 |
|
バーコード - インデックス |
オプションで、バーコードまたはQRコードのインデックスを指定すると、一致するものを絞り込むことができます。 以下の値のいずれかを入力します。
|
|
バーコード - 値 |
実行したいアクションを指定します。 |
|
|
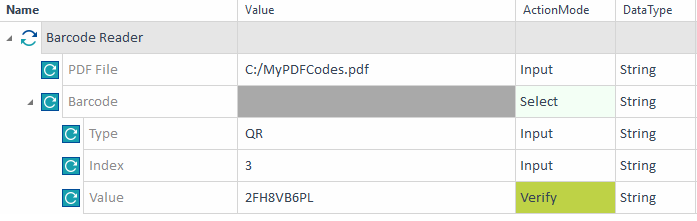
この例では、 C: ドライブにある MyPDFCodes.pdf というPDFドキュメント内の3番目のQRコードを検証します。期待値は 2FH8VB6PL です。
QRコードの検証例 |
Extract Links
Extract Linksモジュールを使用すると、任意のPDF内のリンクを抽出してバッファに格納し、配列として扱うことができます。バッファされたリンクは、後のテストステップで使用できます。Toscaは自動的にすべてのリンクを見つけるため、PDFをスキャンする必要はありません。
モジュールには、以下のモジュール属性があります。
|
ModuleAttribute |
説明 |
|---|---|
|
PDF File |
ファイル名および拡張子を含む、PDFのフルパスを入力します。 |
|
Indexes |
必要に応じて、バッファに格納したいリンクのインデックス位置を指定します。インデックス番号は1から始まります。たとえば「 1-3;5 」と指定すると、1番目、2番目、3番目、および5番目のリンクがバッファに格納されます。 すべてのリンクをバッファするには、このフィールドを空白のままにしてください。 |
|
Links |
PDFから抽出されたリンクを格納するバッファの名前を入力します。 |
|
|
この例では、PDFからリンクを抽出して、後のテストステップで使用するためにバッファします。
PDFからリンクを抽出する |
