Extract links from PDF files
With the PDF Engine 3.0 Module Extract Links, you can easily buffer links inside a PDF file—no need to scan it. Tosca automatically finds and retrieves the links for you.
Buffer links
To buffer links in a PDF file, follow these steps:
-
Create a TestCase from the Extract Links Module.
-
Specify the PDF File with the full path of the PDF, including the file name and extension.
-
Optionally, specify which links you want to buffer. If your PDF file contains multiple links, Tosca buffers all of them as an array. By default, your TestSteps use the first link from the array.
-
To use a specific link, set Indexes to the link's position in the array. For instance, enter 3 if you want to use the third link.
-
To use multiple links, set Indexes to the links' position in the array. For instance, enter 1-3 if you want the first, second, and third links.
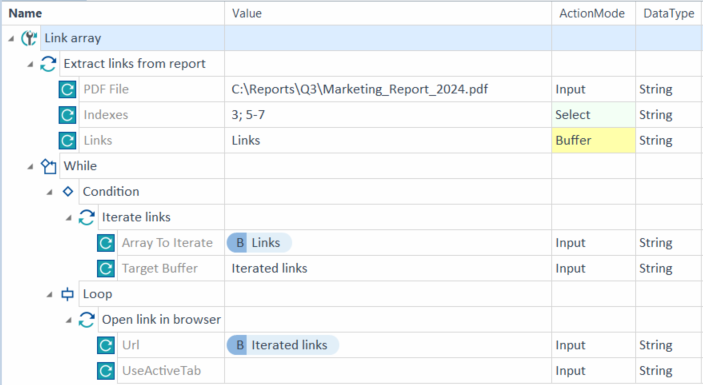
If you buffer multiple links, you need to iterate the buffered array in the following TestSteps. See the example below.
-
-
Set up the buffer via Links. Name your buffer and select the ActionMode Buffer.

|
In this example, you extract several links from a PDF. You want only the third, fifth, sixth, and seventh links in your buffer.
Iterate an array of extracted links |