正規表現
Toscaは正規表現をサポートしており、ターゲット属性が正規表現にマッチする文字列を含んでいるかどうかを比較するために使用されます。通常の表現はダブルクォーテーションで囲んでください。
.NET Frameworkの構文が、Tosca TBoxの正規表現に対して使用されます。
|
構文: |
{REGEX["正規表現"]} 正規表現で引用符を適切に使用できるようにするには、リーディングエスケープ文字が必要となります。 |

|
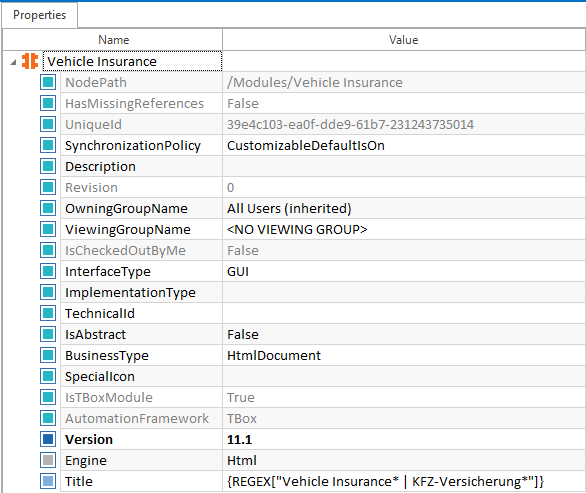
アプリケーションの開始ページには、ステアリングされるリンクが含まれています。このリンクには一意のIDがなく、ドイツ語または英語のテキスト(DEまたはEN)として表示することができます。 両方の言語でページの検索を容易にするために、モジュールレベルのキャプションパラメータに正規表現を指定できます: {REGEX["^TOSCA HTML"]} 。
モジュールレベルの正規表現 現在有効になっている言語に関係なく、リンクをクリックするのに、モジュール レベルの Idパラメータに正規式を指定できます:{REGEX["SpracheTable|LanguageTable"]}
ModuleAttributeレベルの正規表現 |
乱数と正規表現
ランダムテキストは正規表現を使って指定します。表現はダブルクォーテーションで囲んでください。
|
構文: |
{RANDOMREGEX["<Regular expression>"]} |
|
|
{RANDOMREGEX["^[A-Z][a-z]+[0-9]{4}$"]} A~Zの大文字で始まり、任意の数の小文字と0~9の間の4桁の数字が続く値が生成されます。「 ^ 」文字は行の始まりを示し、「 $ 」文字は行の終わりを示します。 例えば、 Ecqwp1989 という表現を生成します。 |
正規表現とバッファ
バッファと正規表現は、バッファが正規表現の一部である場合にのみ使用できることに注意してください。
|
構文: |
{REGEX["正規表現"{B[BufferName]}"正規表現"]} |
|
|
{REGEX[{B[B_12345]} "(iteration [0-9]{4})"]} 例えば、この表現は次の文字列「 E610Overviewprocess (iteration 0012) 」を検証するのに使用できます。この例では、 E610Overviewprocess という値がバッファ「 B_12345 」に事前に書き込まれていることが前提となります。 |
正規表現のほかの例については、 chapter "スキャン結果を管理する" も参照してください。
正規表現を使用したテキストの抽出
正規表現を使用して、文字列の動的部分を確認および抽出できます。Toscaはこれらの値を後で使用するためにバッファに保存します。
名前付きグループは、バッファの名前と値の必須パターンを指定します。
アクションモードの「検証」を使用します。
|
構文: |
{REGEX["expression(?<buffer name>subexpression)expression"]} 表現: 静的部分を指定する任意の正規表現。 バッファ名: 比較の動的部分が保存されるバッファの名前です。 部分表現:バッファリングされるべき動的部分を定義します。 |
(?<buffer name>subexpression) という部分は「名前付きグループ」と呼ばれます。
名前付きグループのバッファ名には、少なくとも1つの単語文字を含める必要があることにご注意ください。
|
|
この例では、Toscaは「 userinfo 」ラベルからユーザー名を抽出しています。 アプリケーションでは、ラベルに、welcomeメッセージとする単語とユーザー名が表示され、感嘆符が続きます。いくつか例を挙げましょう。
「 userinfo 」の表現は、このラベルのテキストがパターンにマッチするかどうかを検証し、ユーザー名を「 username 」バッファに格納します。 {Regex["[a-z]* (?<username>[a-z|\d]*)!"]} パターンには以下が含まれます。
テキストのバッファ部分 |
