テキストファイル
テキストファイルのさまざまなテストを作成するには、以下の手順を実行する必要があります。
-
テキストファイルを読み込みます。
-
ファイルに対してテストを実行します。テスト時に、ToscaはテキストファイルをSQLiteデータベースに読み込みます。
-
テキストファイルに対して事前スクリーニングテストを実行し、間違ったデータが読み込まれるのを防ぎます。
これを行うには、 Tosca Data Integrity Modules And Samples.tsu サブセットに含まれており、「モジュール」->「 Data Integrity Testing 」のフォルダーに格納されている以下のモジュールを使用します。
-
キャッシュデータベースへのファイルのロード
-
キャッシュデータベースに対する定義済みファイルテスト
-
行ごとの完全な比較
-
メタデータの比較
-
JSON/XML ファイルをキャッシュデータベースにロードする
前提条件
CSVファイルを使用する場合は、 RFC 4180 で推奨されている形式を使用します。これにより、 Tricentis Data Integrity がファイルを適切に処理できるようになります。
キャッシュデータベースへのファイルのロード
テキストファイルの中身をSQLiteデータベースに読み込ませるには、「キャッシュデータベースへのファイルのロード」モジュールを使用します。このモジュールを使用して複数のファイルを読み込むことが可能です。
Tosca Commander の「設定」ダイアログで、SQLiteキャッシュデータベースのパスを構成してください(see chapter "設定 - Tricentis データ整合性")。

|
この例では、ファイル「SalesLT.アドレスSemiColon.txt 」をテーブル「アドレス」に読み込んでいます。 ファイルの列はセミコロンで区切られます。最初の行にはヘッダー名が含まれています。
文字区切りのファイルを読み込む |
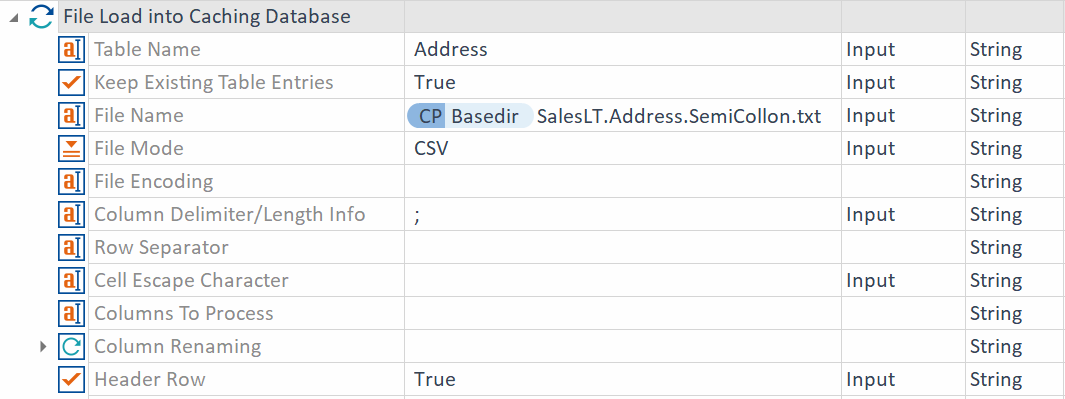
「 キャッシュデータベースへのファイルのロード」モジュールには、以下の属性が含まれています。
|
ModuleAttribute |
説明 |
オプション |
|---|---|---|
|
テーブル名 |
Data Integrity がデータをロードするSQLiteテーブルの名前を入力します。 |
|
|
既存のテーブルエントリを保持する |
「 TRUE 」に設定すると、テキストファイルのデータが既存のテーブルに追加されます。それ以外の場合、 Data Integrity は、新しいデータを読み込む前にテーブルを削除します。 |
X |
|
ファイル名 |
読み込むテキストファイルのフルパスとファイル名を入力してください。同じディレクトリから複数のファイルを同じテーブルに読み込むことができます。 必要に応じてワイルドカードを使用できます。例えば、 C:\temp\myExcelFile*.csv のように入力できます。 |
|
|
ファイルモード |
カラムが固定長、またはカンマで区切られているかどうかを定義します。 |
|
|
ファイルエンコーディング |
ファイルのエンコーディング形式。デフォルト値は UTF8 です。 これらのファイルエンコーディング形式を指定できます。
サポートされているエンコーディングの完全なリストについては、Microsoftのドキュメント(新しいタブで開きます)確認してください。 |
X |
|
列の区切り文字/長さ情報 |
各列の開始点をコンマ区切りのリストで指定するか、文字区切りのファイルでは区切り記号で指定します。 |
|
|
Row Separator |
新しい行を示す文字を指定します。Windowsでは \r\n 、Unixでは \n を使用します。 デフォルト値は、 \r\n または \n です。 |
X |
|
CellEscape Character |
新しい文字ロジックを呼び出す文字を指定します。デフォルト値は「 "」です。 セル値に列区切り文字としても機能する文字や、セルエスケープ文字自体が含まれている場合は、その値をセルエスケープ文字で囲みます。これにより、セルの値の元の意味や機能が保持されます。セルエスケープ文字として設定できるのは、1文字のみです。 例: カンマ(,)は列の区切り文字であり、二重引用符(")はセルのエスケープ文字です。 |
X |
|
処理する列 |
セミコロン区切りロードするカラムのリストを指定します。 デフォルトでは、 Data Integrity はすべての列を読み込みます。 |
X |
|
Column Renaming |
ファイル経由で列の名前を変更します。 列マッピングを含むテキストファイルまたはCSVファイルへの完全なファイルパスを指定します。このファイルは、ヘッダー行 Current Column Name;Mapped Column Name で始まり、そのあとに名前を変更する列ごとに1行ずつ記入されている必要があります。例: Current Column Name;Mapped Column Name Name1;First Name Name2;Last Name |
X |
|
Column Renaming - <Current Name> |
列の名前を手動で変更します。 「 名前」列で、名前を変更する列の名前を指定します。「 値」列で、新しい名前を指定します。 |
X |
|
ヘッダー行 |
ファイルにヘッダー行があるかどうかを示すには、「 TRUE 」に設定します。デフォルトでは、ヘッダー行はありません。 ヘッダーが別の行にある場合は、「 TRUE 」ではなく「 #<n> 」を使用して行番号を指定します。 1行のヘッダーのみがサポートされます。 |
X |
|
で始まる行をスキップ |
セミコロン区切りスキップする値のリストを指定します。 |
X |
|
以下で始まる行のみ: |
セミコロン区切り有効な行を示す文字のリストを定義します。 例えば、「 _ 」、「 - 」、「 < 」で始まるプロセス行は、「 _;-;< 」と指定します。 |
X |
|
セルの設定 - すべての列 - オプション |
以下に記載されているアクションのいずれかを、すべての列に適用します。 |
X |
|
Cell Settings - Single Columns - <Name> |
以下に記載されているアクションのいずれかを、指定した列に適用します。列を指定するには、 <Name> を列名に置き換えます。 |
X |
|
ロードエラーの動作 - ロードエラーを無視 |
ロードエラーを無視するかどうかを定義します。 デフォルト値は「 False 」です。 |
X |
|
ロードエラー動作 - 最大エラー数 |
Tosca が実行を中断するまでの最大エラー数を定義します。 デフォルト値は「 100 」です。 |
X |
|
ロードエラーの動作 - ファイル名 |
エラーが記録されるファイルを指定します。フルパスとファイル名を入力してください。Data Integrity は、同じ名前の既存のファイルを上書きします。 デフォルトでは、 Data Integrity はロードエラーを記録しません。 |
X |
「 セル設定 - すべての列」および「セル設定 - 単一列」は、以下のアクションで使用できます。
|
アクション |
説明 |
|---|---|
|
トリム |
リーディングと後続の空白文字をすべて削除します。 デフォルトのスコープ: HeaderAndData |
|
Trim[<character>] |
指定された文字が先頭と末尾に出現する場合に、すべて削除します。 デフォルトのスコープ: HeaderAndData <character> を削除する文字に置き換えます。 例:「 " 」を削除するには、「 " 」を4回入力します: Trim[""""] 。 |
|
TrimStart |
リーディングの空白文字をすべて削除します。 デフォルトのスコープ: HeaderAndData |
|
TrimStart[<character>] |
指定された文字がリーディングに出現する場合はすべて削除します。 デフォルトのスコープ: HeaderAndData <character> を削除する文字に置き換えます。 例:「 " 」を削除するには、「 " 」を4回入力します: Trim[""""] 。 |
|
TrimEnd |
後続の空白文字をすべて削除します。 デフォルトのスコープ: HeaderAndData |
|
TrimEnd[<character>] |
指定された文字が末尾に出現する場合はすべて削除します。 デフォルトのスコープ: HeaderAndData <character> を削除する文字に置き換えます。 例:「 " 」を削除するには、「 " 」を4回入力します: Trim[""""] 。 |
|
Replace[<search string>][<replace string>] |
最初の文字列のすべての出現箇所を2番目の文字列に置き換えます。 デフォルトのスコープ:データ |
|
Substring[<start index>] |
長い文字列の一部を抽出します。抽出は、指定された開始インデックス位置から始まり、文字列の末尾まで実行されます。 デフォルトのスコープ:データ 例: Substring[9]で「 Project Manager 」と入力すると、「 Manager 」が返されます。 |
|
Substring[<start index>][<length>] |
長い文字列の一部を抽出します。抽出は、指定された開始インデックス位置から始まり、長さで指定された文字数が含まれます。 デフォルトのスコープ:データ 例: Substring[9][3]で「 Project Manager 」と入力すると、「 Man 」が返されます。 |
|
Right[<length>] |
長い文字列の一部を抽出します。抽出は、文字列の末尾から先頭に向かって実行され、長さで指定された文字数が含まれます。 デフォルトのスコープ:データ 例: Right[7] で「 Project Manager 」と入力すると、「 Manager 」が返されます。 |
|
小文字 |
現在アクティブなロケールを使って文字列を小文字に変換します。 デフォルトのスコープ:データ 例: Lowercase で「 Project Manager 」と入力すると、「 project manager 」が返されます。 |
|
Lowercase[Culture:<culture name>] |
文字列をすべて小文字に変換します。Lowercase[Culture:<culture name> デフォルトのスコープ:データ 例: Lowercase[Culture:zh-Hans] は、「中国語(簡体字)」の文化情報を使用して、大文字を小文字に変換します。 |
| 大文字 |
現在アクティブなロケールを使って文字列を大文字に変換します。 デフォルトのスコープ:データ 例: Uppercase で「 Project Manager 」と入力すると、「 PROJECT MANAGER 」が返されます。 |
|
Uppercase[Culture:<culture name>] |
文字列をすべて大文字に変換します。Uppercase[Culture:<culture name> デフォルトのスコープ:データ 例: Lowercase[Culture:en-us] は、「英語 - 米国」の文化情報を使用して、小文字を大文字に変換します。 |
アクションのデフォルトのスコープを変更するには、「 Scope 」パラメータを追加します。
-
アクションをヘッダー行のみに適用するには、パラメータ [Scope:Header] を追加します。
-
アクションをヘッダー行以外のすべてのデータ行に適用するには、パラメータ [Scope:Data] を追加します。
-
アクションをヘッダー行とすべてのデータ行に適用するには、パラメータ [Scope:HeaderAndData] を追加します。
|
|
この例では、文字列「 CustomerDataAustria 」のすべてのインスタンスを文字列「 CustomerDataUSA 」に置き換えます。 この変更をヘッダーとすべてのデータ行に適用します。これを行うには、以下のアクションを定義してください。 Replace[<CustomerDataAustria>][<CustomerDataUSA>][Scope:HeaderAndData] |
テストで使用するモジュールを指定する
ワークスペースに複数の「キャッシュデータベースへのファイルのロード」モジュールがある場合は、テストで使用するモジュールを指定する必要があります。それ以外の場合、システムは最初に見つかったモジュールを使用します。
これは、「キャッシュデータベースへのファイルのロード」モジュールの名前が異なる場合にも適用されます。Tosca DI は、適用できるモジュールを確認する際に、名前ではなく構成パラメータ「 SpecialExecutionTask 」を使用します。
使用したいモジュールを指定するには、その設定パラメータを作成する必要があります。これを行うには、以下の手順に従ってください。
-
モジュールを右クリックし、ミニツールバーから「構成パラメータを作成」を選択します。
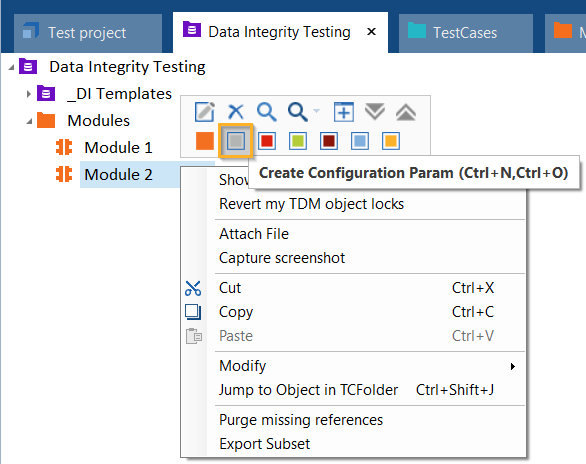
ミニツールバーから構成パラメータを作成する
-
新しい構成パラメータに「 DIWizardUseInAutocreate 」という名前を付けます。
-
値 を「 TRUE 」に設定します。
テスト間でモジュールを切り替えるには、1つのモジュールから設定パラメータを削除し、別のモジュールに追加します。
「DIWizardUseInAutocreate」の値が「 TRUE 」に設定されている「キャッシュデータベースへのファイルのロード」モジュールは、一度に一つにしてください。そうでない場合、 Data Integrity は、最初に見つけたモジュールを使用します。
キャッシュデータベースに対する定義されたファイルテスト
「 キャッシュデータベースモジュールに対する定義済みファイルテスト」モジュールを使用すると、「キャッシュデータベースへのファイルのロード」モジュールを使用して作成したテーブルに対して、定義済みのテストを実行できます。
以下の表は、ウィザードのテストタイプと、モジュールで指定されたそれぞれのテストを示しています。
|
ウィザード・テスト・タイプ |
モジュールテスト |
|---|---|
|
空の値を持たない |
空の値なし |
|
フィールドタイプ |
数値である |
|
最小値 |
最小値 |
|
最大値 |
最大値 |
|
合計 |
合計 |
|
値の範囲 |
値の範囲 |
|
最小長さ |
最小長さ |
|
最大長 |
最大長 |
|
正確な長さ |
長さ |
|
ユニーク |
ユニーク |
|
行数 |
行数 |
さらに、次のテストはモジュールでのみ使用できます:
-
以上
-
より大きいまたは等しい
-
未満
-
未満または等しい
-
間
-
間または等しい
-
発生状況
-
列名が存在するかどうか
「 キャッシュデータベースに対する定義済みファイルテスト」モジュールには、以下の属性が含まれています。
|
ModuleAttribute |
説明 |
|---|---|
|
テーブル名 |
テストしたいテーブルの名前を指定します。 |
|
列 |
分析したい列の名前を指定します。 Data Integrity は、その列内のすべての行をテストします。 |
|
テスト |
使用するテストを指定します。 |
|
パラメータ |
テストの種類によって入力を追加する必要がある場合は、このパラメータを使用します。 例:RowCountテストの場合、予想される行数を入力してください。 |
|
値 |
全体的な結果を確認します。テストに合格すると、メッセージは「 OK 」になります。 このモジュール属性は「ActionMode」検証が必要です。 |
|
|
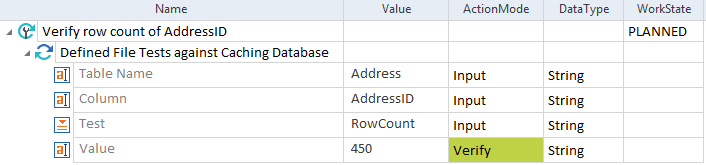
この例では、Data Integrityによって列の行数が検証されています。 「 住所」テーブルの「 AddressID 」列には、 450 行あります。
行数の確認 |
|
Tosca Data Integrity Modules And Samples.tsu サブセットには、さらに多くの例が記載されています。 例は、「サンプルテスト」->「ユースケース別」->「事前スクリーニングテスト」->「ファイルに対して」のフォルダに格納されています。 |