Reguläre Ausdrücke
Tosca TBox unterstützt reguläre Ausdrücke, mit denen verglichen werden kann, ob das Zielattribut eine Zeichenfolge enthält, die dem regulären Ausdruck entspricht. Der reguläre Ausdruck muss in doppelten Hochkommas angegeben werden.
Für die regulären Ausdrücke in der Tosca TBox wird die .NET Framework Syntax verwendet.
|
Syntax: |
{REGEX["Regulärer Ausdruck"]} Wird ein Anführungszeichen im regulären Ausdruck verwendet, muss es mit einem Anführungszeichen als Escape-Zeichen eingeleitet werden. |

|
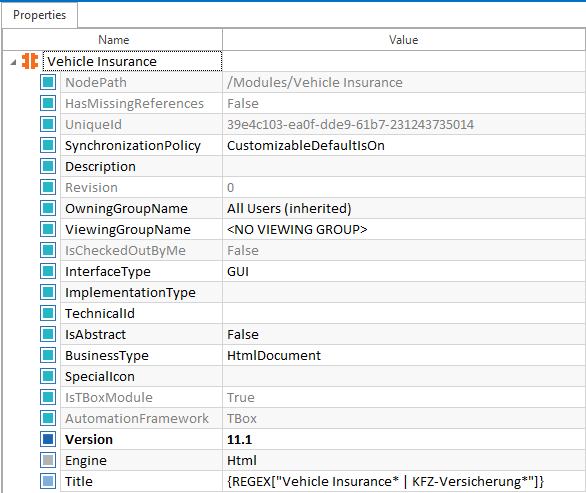
Der Startbildschirm einer Applikation besitzt einen Link, der gesteuert werden soll. Dieser hat keine eindeutige ID und kann mit deutschem oder englischem Text dargestellt sein (DE oder EN). Damit die Seite in beiden Sprachen gefunden wird, kann auf Modul-Ebene für den Parameter Caption ein regulärer Ausdruck definiert werden: {REGEX["^TOSCA HTML"]}
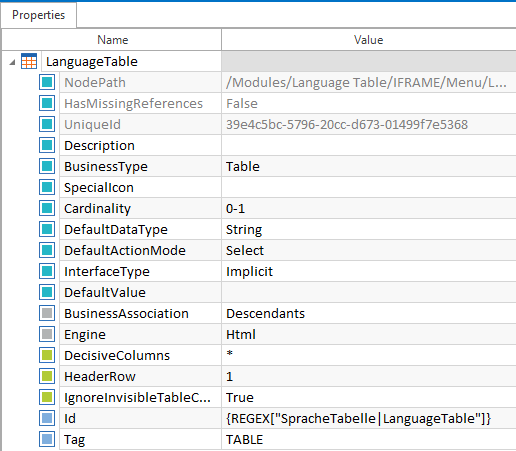
Regulärer Ausdruck auf Modul-Ebene Um den Link anzuklicken, unabhängig von der aktuell aktiven Sprache, kann auf Modulattribut-Ebene für den Parameter Id ein regulärer Ausdruck definiert werden: {REGEX["SpracheTabelle|LanguageTable"]}
Regulärer Ausdruck auf Modulattribut-Ebene |
Zufallszahlen basierend auf regulären Ausdrücken
Ein Zufallstext wird über einen regulären Ausdruck angegeben. Der reguläre Ausdruck muss in doppelten Hochkommas angegeben werden.
|
Syntax: |
{RANDOMREGEX["<Regulärer Ausdruck>"]} |
|
|
{RANDOMREGEX["^[A-Z][a-z]+[0-9]{4}$"]} Es wird ein Wert generiert, der mit einem Großbuchstaben zwischen A-Z beginnt. Danach folgen beliebig viele Kleinbuchstaben und genau vier Ziffern zwischen 0-9. Das Zeichen ^ markiert den Zeilenanfang, das Zeichen $ das Zeilenende. Der Ausdruck erzeugt beispielsweise Ecqwp1989. |
Reguläre Ausdrücke und Buffer
Will man Buffer und reguläre Ausdrücke benutzen, muss berücksichtigt werden, dass das nur möglich ist, wenn der Buffer Teil des regulären Ausdrucks ist:
|
Syntax: |
{REGEX["Regulärer Ausdruck"{B[BufferName]}"Regulärer Ausdruck"]} |
|
|
{REGEX[{B[B_12345]} "(iteration [0-9]{4})"]} Mit dem Ausdruck kann beispielsweise der String E610Overviewprocess (iteration 0012) verifiziert werden. Es wird davon ausgegangen, dass im Buffer B_12345 der Wert E610Overviewprocess zwischengespeichert ist. |
Beispiele für die Verwendung finden Sie in Kapitel "Aufzeichnungsergebnisse verwalten".
Texte mit Hilfe von regulären Ausdrücken extrahieren
Verwenden Sie reguläre Ausdrücke um dynamische Teile einer Zeichenkette zu überprüfen und zu extrahieren. Tosca speichert diese Werte als Buffer für die spätere Verwendung.
In Named Groups geben Sie den Buffernamen und den gewünschten regulären Ausdruck an.
Verwenden Sie die Aktion Verify.
|
Syntax: |
{REGEX["Expression(?<Buffername>Subexpression)Expression"]} Expression: Regulärer Ausdruck, der die statischen Teile bezeichnet. Buffername: Unter diesem Namen wird der dynamische Teil des Vergleichs in einen Buffer gespeichert. Subexpression: definiert den dynamischen Teil, der in den Buffer gespeichert werden soll. |
Der Abschnitt (?<buffer name>subexpression) wird als Named Group bezeichnet.
Bitte beachten Sie, dass der Buffername einer Named Group zumindest einen Buchstaben enthalten muss.
|
|
In diesem Beispiel extrahiert Tosca den Benutzernamen aus dem Label userinfo. In der Applikation wird ein Wort und der Benutzername gefolgt von einem Rufzeichen als Willkommensnachricht angezeigt. Mögliche Beispiele sind:
Der Ausdruck in userinfo überprüft ob der Text in diesem Label dem regulären Ausdruck entspricht und speichert den Benutzernamen in den Buffer username: {Regex["[a-z]* (?<username>[a-z|\d]*)!"]} Der reguläre Ausdruck enthält:
Teile eines Textes in Buffer speichern |
