Modul Load Data into Caching Database from Customization
Mit dem Modul Load Data into Caching Database from Customization können Sie mit Datenquellen arbeiten, die Tricentis Data Integrity standardmäßig nicht unmittelbar unterstützt. Sie können Ihren eigenen benutzerdefinierten Datenquellenleser in Data Integrity integrieren, um jeden Datensatz in die SQLite-Caching-Datenbank zu laden.
Wenn Sie zum Beispiel Datenformate haben, die weniger verbreitet sind und kein ODBC/JDBC-Treiber vorhanden ist (wie bestimmte EBCDIC-Dateien oder Daten, die an Remote-Standorten gespeichert und schwer zugänglich sind), können Sie eine Customisierung schreiben, die die Daten liest und sie wie eine Tabelle formatiert. Sobald Sie Ihre Customisierung in Data Integrity integriert haben, können Sie das Modul Load Data into Caching Database from Customization verwenden, um die Daten in der Caching-Datenbank zu speichern.
Tricentis empfiehlt, diesen Ansatz nur zu verwenden, wenn Sie über das technische Wissen verfügen, eine benutzerdefinierte Implementierung zu schreiben. Informationen zum Einrichten eines benutzerdefinierten Datenquellenlesers finden Sie hier: siehe Kapitel "Benutzerdefinierten Datenquellenleser verwenden".
Voraussetzungen
Um das Modul Load Data into Caching Database from Customization zu verwenden, müssen Sie die folgenden Anforderungen erfüllen:
-
Sie haben die Untermenge Tosca Data Integrity Modules And Samples.tsu.
-
Sie haben den Pfad der SQLite-Caching-Datenbank unter Settings->Tosca Data Integrity konfiguriert.
-
Sie haben Ihren benutzerdefinierten Datenquellenleser wie in Kapitel "Benutzerdefinierten Datenquellenleser verwenden" beschrieben eingerichtet und integriert.
Das Modul verwenden
Die folgenden Tabellen enthalten Informationen zu allen Modulattributen des Moduls Load Data into Caching Database from Customization.
Tabellenname und Tabelleneinträge
|
Modulattribut |
Beschreibung |
Optional |
|---|---|---|
|
Table Name |
Geben Sie den Namen der Tabelle an, in die Tosca DI die Daten lädt. |
|
|
Keep Existing Table Entries |
Setzen Sie den Wert auf True, um die Daten der Datei zur vorhandenen Tabelle hinzuzufügen. Der Standardwert ist False. Dies bedeutet, dass Tosca DI die Tabelle vor dem Laden neuer Daten verwirft. |
X |
Benutzerdefinierter Datenleser
|
Modulattribut |
Beschreibung |
Optional |
|---|---|---|
|
Class Attribute Name |
Geben Sie im Feld Value den Namen Ihres benutzerdefinierten Datenquellenlesers ein. Der Name wird im ClassAttributeName Ihrer Datenquellenschnittstelle deklariert. Beispiel: CustomCSVReader |
|
|
Parameters - Key |
Geben Sie das Schlüssel-Wert-Paar an, um Informationen an Ihren benutzerdefinierten Implementierungscode zu übergeben:
Beispiel: Name FilePath, Wert D:\TestFile.csv Hinweis: Wenn Sie mit COBOL-Dateien arbeiten, müssen Sie bestimmte Parameter verwenden (siehe Kapitel "Tests mit COBOL-Dateien ausführen"). |
|
Spalten umbenennen
Column Renaming funktioniert entweder per Datei oder manuell. Sie können nicht beides festlegen.
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Column Renaming |
Ordnen Sie die Spaltennamen über eine Datei neu zu. Geben Sie den vollständigen Dateipfad zu einer Text- oder CSV-Datei mit den Spaltenzuordnungen an. Die Datei muss mit der Kopfzeile Aktueller Spaltenname;Zugeordneter Spaltenname, gefolgt von einer Zeile für jede Spalte, die Sie umbenennen möchten, beginnen. Beispiel: Aktueller Spaltenname;Zugeordneter Spaltenname Name1;Vorname Name2;Nachname |
X |
|
Current Name |
Ordnen Sie die Spaltennamen manuell neu zu. Geben Sie in der Spalte Name den Namen der Spalte an, die Sie umbenennen möchten. Geben Sie in der Spalte Value den neuen Namen an. |
X |
Zellenoptionen
Cell settings enthält zwei Optionen:
-
All Columns - Option wendet eine der folgenden Aktionen auf alle Spalten an.
-
Single Columns - <Name> wendet eine der folgenden Aktionen auf eine angegebene Spalte an. Um eine Spalte anzugeben, ersetzen Sie <Name> durch den Spaltennamen.
|
Wert |
Beschreibung |
Optional |
|---|---|---|
|
Trim |
Entfernt alle führenden und nachfolgenden Leerräume. Standardeinstellung: HeaderAndData |
X |
|
Trim[<character>] |
Entfernt alle führenden und abschließenden Vorkommen des angegebenen Zeichens. Standardeinstellung: HeaderAndData Ersetzen Sie <character> durch das zu entfernende Zeichen. Um ein " zu entfernen, geben Sie das " vier Mal ein, z. B. Trim[""""]. |
X |
|
TrimStart |
Entfernt alle führenden Leerräume. Standardeinstellung: HeaderAndData |
X |
|
TrimStart[<character>] |
Entfernt alle führenden Vorkommen des angegebenen Zeichens. Standardeinstellung: HeaderAndData Ersetzen Sie <character> durch das zu entfernende Zeichen. Um ein " zu entfernen, geben Sie das " vier Mal ein, z. B. TrimStart[""""]. |
X |
|
TrimEnd |
Entfernt alle nachfolgenden Leerzeichen. Standardeinstellung: HeaderAndData |
X |
|
TrimEnd[<character>] |
Entfernt alle abschließenden Vorkommen des angegebenen Zeichens. Standardeinstellung: HeaderAndData Ersetzen Sie <character> durch das zu entfernende Zeichen. Um ein " zu entfernen, geben Sie das " vier Mal ein, z. B. TrimEnd[""""]. |
X |
|
Replace[<string>][<string>] |
Ersetzt alle Vorkommen der ersten durch die zweite Zeichenfolge. Standardeinstellung: Data |
X |
|
Substring[<start index>] |
Extrahiert einen Teil einer längeren Zeichenfolge. Das Extrahieren beginnt an der definierten Position start index und wird bis zum Ende der Zeichenfolge ausgeführt. Standardeinstellung: Data Beispiel: Substring[9] mit Eingabe Project Manager gibt Manager zurück. |
X |
|
Substring[<start index>][<length>] |
Extrahiert einen Teil einer längeren Zeichenfolge. Das Extrahieren beginnt an der definierten Position start index und enthält die Anzahl der in length angegebenen Zeichen. Standardeinstellung: Data Beispiel: Substring[9][3] mit Eingabe Project Manager gibt Man zurück. |
X |
|
Right[<length>] |
Extrahiert einen Teil einer längeren Zeichenfolge. Das Extrahieren wird vom Ende der Zeichenfolge in Richtung des Anfangs ausgeführt und enthält die Anzahl der in length angegebenen Zeichen. Standardeinstellung: Data Beispiel: Right[7] mit Eingabe Project Manager gibt Manager zurück. |
X |
|
Lowercase |
Konvertiert die Zeichenfolge unter Verwendung des aktuell aktiven Gebietsschemas in Kleinbuchstaben. Standardeinstellung: Data Beispiel: Lowercase mit Engabe Project Manager gibt project manager zurück. |
X |
|
Lowercase[Culture:<culture name>] |
Konvertiert die gesamte Zeichenfolge in Kleinbuchstaben. Lowercase[Culture:<culture name>] verwendet den gegebenen Kulturnamen, um ein neues Gebietsschema zu erstellen. Standardeinstellung: Data Beispiel: Lowercase[Culture:zh-Hans] verwendet die Kulturinformationen von "Chinese(simplified)", um die Groß- in Kleinbuchstaben zu konvertieren. |
X |
|
Uppercase |
Konvertiert die Zeichenfolge unter Verwendung des aktuell aktiven Gebietsschemas in Großbuchstaben. Standardeinstellung: Data Beispiel: Uppercase mit Eingabe Project Manager gibt PROJECT MANAGER zurück. |
X |
|
Uppercase[Culture:<culture name>] |
Konvertiert die gesamte Zeichenfolge in Großbuchstaben. Uppercase[Culture:<culture name>] verwendet den gegebenen Kulturnamen, um ein neues Gebietsschema zu erstellen. Standardeinstellung: Data Beispiel: Lowercase[Culture:en-us] verwendet die Kulturinformationen von "English - United States", um die Klein- in Großbuchstaben zu konvertieren. |
X |
|
Trim double quotes |
Entfernt führende und nachfolgende doppelte Anführungszeichen. Beispiel: Trim double quotes mit der Eingabe """Projektmanager""" gibt Projektmanager zurück. |
X |
Verhalten bei Ladefehlern
|
Modulattribut |
Beschreibung |
Optional |
|---|---|---|
|
Ignore Load Errors |
Geben Sie an, ob Tosca DI Ladefehler ignorieren soll. Der Standardwert ist False. Dies bedeutet, dass Fehler nicht ignoriert werden. |
X |
|
Max Errors |
Geben Sie die maximale Anzahl von Fehlern an, bevor die Ausführung abgebrochen wird. Der Standardwert ist 100. |
X |
|
File Name |
Geben Sie die Datei an, in der Fehler protokolliert werden. Geben Sie einen vollständigen Pfad und Dateinamen ein. Tosca DI überschreibt eine gegebenenfalls vorhandene Datei mit dem gleichen Namen. Standardmäßig protokolliert Tosca DI keine Ladefehler. |
X |
Beispiel: Daten aus einer CSV-Datei laden
In diesem Beispiel verwenden Sie das Modul Load Data into Caching Database from Customization, um Daten aus einer CSV-Datei in die Caching-Datenbank zu laden. Sie verwenden dazu einen benutzerdefinierten CSV-Dateileser (siehe unser Codebeispiel). Sie führen die folgenden Schritte aus:
-
Um den benutzerdefinierten Datenquellenleser zu integrieren, kopieren Sie die DLL-Datei in den Ordner Custom Data Readers unter C:\Programme (x86)\TRICENTIS\Tosca Testsuite\Data Integrity.
-
Sie öffnen in Tricentis Tosca den Testschritt Load Data into Caching Database from Customization.
-
Als Table Name geben Sie den Namen der Tabelle an, in die Tosca DI die Daten lädt.
-
Sie geben im Feld Value von Class Attribute Name den Namen Ihres benutzerdefinierten Datenquellenlesers ein.
-
Sie wählen Parameters->Key und ändern den Namen Key in FilePath.
-
Sie geben im Feld Value den Dateipfad der CSV-Datei ein, die Sie als Datenquelle verwenden möchten.
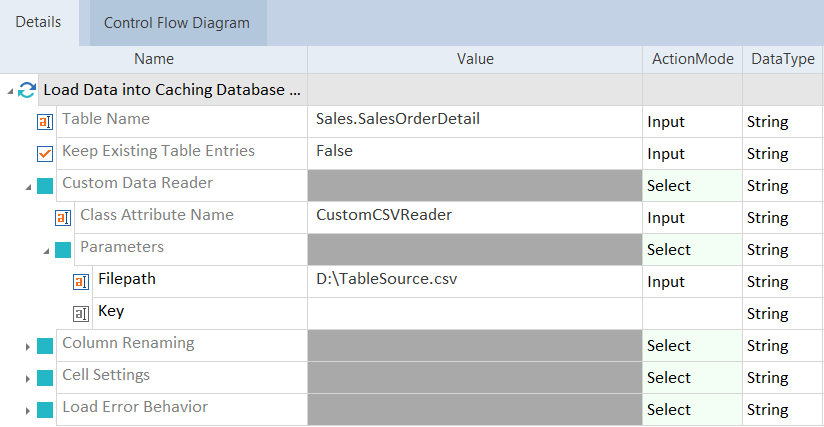
Daten aus einer CSV-Datei in die Caching-Datenbank laden
Sie können nun Ihren Testfall ausführen.