許容範囲 を定義する
行ごとの比較の目的は、ソース行とターゲット行の一致のデータを確認することです。行がすべての列で一致しない場合、 Tricentisデータ整合性はそれらを不一致とみなします。
ただし、許容誤差を使用して、比較した値間のどの差が許容できるかを定義することができます。これにより、 Data Integrity は、ソースとターゲットの値にわずかな違いがあったとしても、一致とみなします。
許容範囲はどのように定義するのですか?
最低許容値から最高許容値までの範囲を定義したい場合は、以下のいずれかの形式を使用してください。
-
セミコロンで区切られた負の数値1つ、および正の数値1つ。例: -2; +2 。
-
セミコロンで区切られた、負のパーセンテージ値1つ、および正のパーセンテージ値1つ。例: -5%; +5% 。
より低い許容値またはより高い許容値のみを定義したい場合は、以下のいずれかの形式を使用してください。
-
負の数値1つまたは正の数値1つ。例: -2 。
-
負のパーセンテージ値1つ、または正のパーセンテージ値1つ。例: +5% 。

|
「 行キー」の列に許容範囲は使用できません。「行キー」は一意である必要があり、完全一致です。 |
許容値の指定
行ごとの比較テストケースで列の許容範囲を指定できます。
これを行うには、以下の手順に従ってください。
-
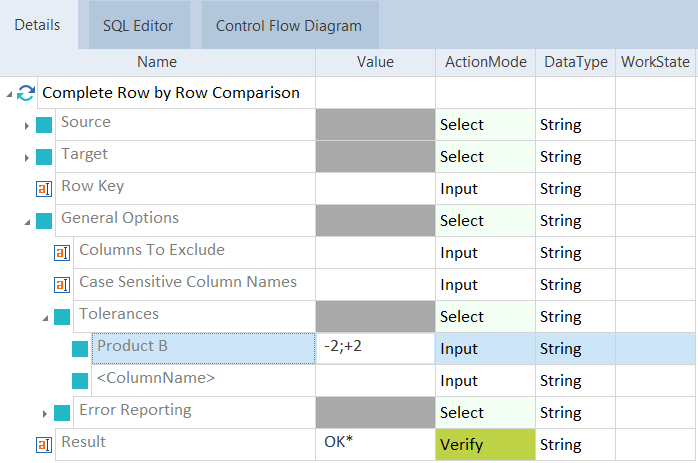
「 一般オプション 」->「 許容範囲」に移動します。以下のテストステップ値で、必要な各列の許容範囲を直接定義します。
-
「 名前」列に列の名前を入力します。
-
「 値」列で、必要に応じて許容範囲を指定します。

|
この例では、ソース列「製品 A 」に値「 33.8 」が含まれています。対象列の「製品B 」では、この値が異なる場合があります。 最小目標値「31.8」、最大目標値「35.8」を許容する場合は以下のようになります。 この許容範囲を指定するには、対象列 「製品 B 」に値「 -2;+2 」を入力します。
指定許容範囲は「 -2;+2 」となります。 |
小数と千の桁区切りにロケールを選択します。
許容範囲が列に適用される前に、 Tricentis Tosca は列を数値に変換します。Tricentis Tosca は数字の書式に米国英語を使用しています。つまり、コンマ(,)がデフォルトの千の桁区切り文字で、ドット(.)がデフォルトの小数区切り文字です。このロケールは、ソースとターゲットの両方で変更できます。これを行うには、以下の手順に従ってください。
-
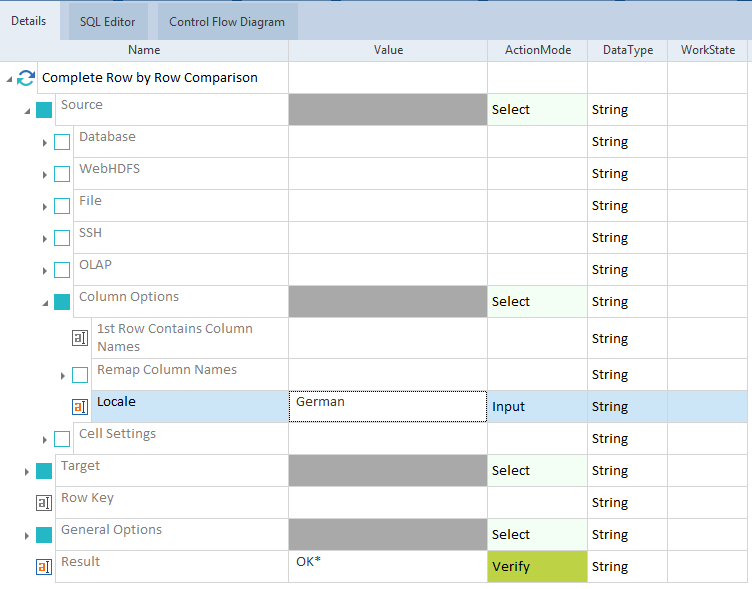
「 ソース」または「ターゲット」の「列オプション」に移動します。
-
ロケールのために、ドロップダウンメニューから言語を選択してください。
このリストには、一つの言語のすべての方言も含まれます。例えば、ドイツ語(リヒテンシュタイン)ロケールを使用すると、千の区切りとしてピリオドの代わりに単一の引用符を使用します。
あるいは、システム文化を選択することもできます。つまり、データが存在するシステムのデフォルトロケール。
言語を選択する