カスタマイズモジュールからキャッシュデータベースへのデータの読み込み
カスタマイズモジュールからキャッシュデータベースにデータを読み込むと、 Tricentisデータ整合性がサポートしていないデータソースをそのまま使用することができます。任意のデータセットを SQLiteキャッシュデータベースに読み込むために、独自のカスタムデータソースリーダーをデータ整合性に統合することができます。
例えば、ある種のEBCDICファイルや、遠隔地に保存されていてアクセスが困難なデータなど、一般的でなくODBC/JDBCドライバが存在しないデータ形式がある場合、データを読み込んでテーブルのようにフォーマットするカスタマイズを書くことができます。カスタマイズをデータ整合性に統合したら、カスタマイズモジュールからキャッシュデータベースにデータを読み込んで、キャッシュデータベースにデータを保存することができます。
Tricentis は、カスタム実装を書く専門知識がある場合にのみ、この方法の使用をお勧めしています。カスタムデータソースリーダー see chapter "カスタムデータソースリーダーを使用する" を設定する方法については、こちらをご覧ください。
必須条件
カスタマイズモジュールからキャッシュデータベースへのデータの読み込みを使用するには、以下の条件を満たす必要があります:
-
Tosca データ整合性Modules および Samples.tsu サブセットがあります。
-
設定->;Tosca Data Integrityで SQLiteキャッシュデータベースのパスを設定しました。
-
カスタムデータソースリーダーを以下の説明 chapter "カスタムデータソースリーダーを使用する" に従って設定して統合しました。
モジュールを使用
以下のテーブルには、カスタマイズモジュールからキャッシュデータベースにデータを読み込む際の、すべての モジュール属性に関する情報があります。
テーブル名とテーブルエントリ
|
ModuleAttribute |
説明 |
オプション |
|---|---|---|
|
テーブル名 |
Tosca DI がデータを読み込むテーブル名を指定します。 |
|
|
既存のテーブルエントリの保持 |
ファイルのデータを既存のテーブルに追加するには、 TRUE を設定します。 デフォルト値は False です。これは、 Tosca DI が新しいデータを読み込む前にテーブルを削除することを意味します。 |
X |
カスタムデータリーダー
|
ModuleAttribute |
説明 |
オプション |
|---|---|---|
|
クラス属性名 |
値 のフィールドに、カスタムデータソースリーダーの名前を入力します。名前はデータソースインターフェースのクラス属性名に記載されています。 例: CustomCSVReader |
|
|
パラメータ - キー |
キーと値のペアを指定して、カスタム実装コードに情報を渡します。
例:名前 FilePath 、値 D:\TestFile.csv 注意: COBOL ファイルを使用する場合は、特定のパラメータ (see chapter "COBOLファイルを使ったテストの実行") を使用する必要があります。 |
|
カラム名の変更
カラム名の変更は、ファイルまたは手動で行います。両方を指定することはできません。
|
値 |
説明 |
オプション |
|---|---|---|
|
カラム名の変更 |
ファイル経由でカラム名を再マッピングします。 列マッピングでテキストファイルまたはCSVファイルへの完全なファイルパスを指定します。このファイルは、ヘッダー行現在のカラム名;マップされたカラム名で始まり、その後に名前を変更するカラムごとに 1 行ずつ続く必要があります。 例: Current Column Name;Mapped Column Name Name1;First Name Name2;Last Name |
X |
|
現在の名前 |
カラム名を手動でリマップします。 名前のカラムで、名前を変更したいカラムの名前を指定します。値 のカラムで、新しい名前を指定します。 |
X |
セル設定
セルの設定には2つのオプションがあります:
-
すべてのカラム - オプションは、以下のアクションのいずれかをすべてのカラムに適用します。
-
単一のカラム - 以下のアクションのいずれかを指定したカラムにを適用します。 <Name>カラムを指定するには、 <Name> をカラム名に置き換えてください。
|
価値 |
説明 |
オプション |
|---|---|---|
|
トリム |
リーディングと後続ホワイトスペースのすべての文字を削除します。 デフォルトのスコープ: HeaderAndData |
X |
|
Trim[<character>] |
指定された文字の先頭および末尾の部分をすべて削除します。 デフォルトのスコープ:HeaderAndData <character> を削除したい文字と交換します。 " を削除するには、 Trim[""””] のように " を4回入力します。 |
X |
|
トリムスタート |
リーディングホワイトスペースの文字をすべて削除します。 デフォルトのスコープ: HeaderAndData |
X |
|
TrimStart[<character>] |
指定された文字の先頭の部分をすべて削除します。 デフォルトのスコープ:HeaderAndData <character> を削除したい文字と交換します。 " を削除するには TrimStart[""””] のように " を4回入力します。 |
X |
|
TrimEnd |
後続のホワイトスペースの文字をすべて削除します。 デフォルトのスコープ: HeaderAndData |
X |
|
TrimEnd[<character>] |
指定された文字の後続の部分をすべて削除します。 デフォルトのスコープ:HeaderAndData <character> を削除したい文字と交換します。 " を削除するには、 TrimEnd[""""] のように " を4回入力します。 |
X |
|
Replace[<string>][<string>] |
最初の文字列のすべての部分を第二の文字列に置き換えます。 デフォルトのスコープ:Data |
X |
|
Substring[<start index>] |
長い文字列の一部を抽出します。 抽出は、定義された開始インデックスの位置から始まり、文字列の終わりまで実行されます。 デフォルトのスコープ:Data 例: Substring[9] で Project Manager と入力すると Manager となります。 |
X |
|
Substring[<start index>][<length>] |
長い文字列の一部を抽出します。 抽出は、定義された開始インデックスの位置から始まり、長さで指定された文字数を含みます。 デフォルトのスコープ:Data 例: Substring[9][3] で Project Manager と入力すると Man となります。 |
X |
|
Right[<length>] |
長い文字列の一部を抽出します。 抽出は文字列の終わりから始まりに向かって実行され、長さで指定された文字数を含みます。 デフォルトのスコープ:Data 例: Right[7] で、 Project Manager と入力すると Manager となります。 |
X |
|
小文字 |
現在アクティブなロケールを使って文字列を小文字に変換します。 デフォルトのスコープ:Data 例: Project Manager と小文字で入力すると、 project manager となります。 |
X |
|
Lowercase[Culture:<culture name>] |
文字列をすべて小文字に変換します。Lowercase[Culture:<culture name>] は、指定されたカルチャ名を使用して新しいロケールを作成します。 デフォルトのスコープ: データ 例えば、 Lowercase[Culture:zh-Hans ]は "Chinese(simplified) " のカルチャ情報を使って大文字を小文字に変換します。 |
X |
|
大文字 |
現在アクティブなロケールを使って文字列を大文字に変換します。 デフォルトのスコープ:Data 例: Project Manager と大文字で入力すると、 PROJECT MANAGER となります。 |
X |
|
Uppercase[Culture:<culture name>] |
文字列をすべて大文字に変換します。Uppercase[Culture:<culture name>]は、指定されたカルチャ名を使用して新しいロケールを作成します。 デフォルトのスコープ: データ 例: Lowercase[Culture:en-us]は "English - United States" のカルチャ情報を使って小文字を大文字に変換します。 |
X |
|
二重引用符をトリミング |
リーディングと後続の二重引用符を削除します。 例:二重引用符を使って """Project Manager""" と入力すると、 Project Manager となります。 |
X |
ロードエラーの動作
|
ModuleAttribute |
説明 |
オプション |
|---|---|---|
|
ロードエラーを無視 |
Tosca DI が読み込みエラーを無視するかどうかを指定します。 デフォルト値は False です。これはエラーが無視されないことを意味します。 |
X |
|
最大エラー数 |
実行が中断されるまでの最大エラー数を指定します。 デフォルト値は 100 です。 |
X |
|
ファイル名 |
エラーが記録されるファイルを指定します。フルパスとファイル名を入力してください。Tosca DI は、同じ名前の既存のファイルを上書きします。 デフォルトでは、 Tosca DI は、読み込みエラーを記録しません。 |
X |
例:CSVファイルからデータを読み込む
この例では、カスタマイズモジュールからキャッシュデータベースへのデータの読み込みを使用して、CSVファイルからキャッシュデータベースにデータを読み込みます。そのためには、カスタムCSVファイルリーダーを使用します(コードサンプルを参照してください)。以下の手順を実行します:
-
カスタムデータソースリーダーを統合するには、DLL ファイルをコピーして、 C:\Program Files (x86)\TRICENTIS\Tosca Testsuite\Data Integrity にあるカスタム データ リーダーフォルダにペーストします。
-
Tricentis Toscaでは、カスタマイズテストステップからキャッシュデータベースに読み込んだデータを開きます。
-
テーブル名として、 Tosca DI がデータを読み込むテーブル名を指定します。
-
クラス属性名の値のフィールドには、カスタムのデータソースリーダーの名前を入力します。
-
[パラメータ]- >[キー] を選択し、名前の [キー] を [ファイルパス] に変更します。
-
値 のフィールドには、データソースとして使用するCSVファイルのファイルパスを入力します。
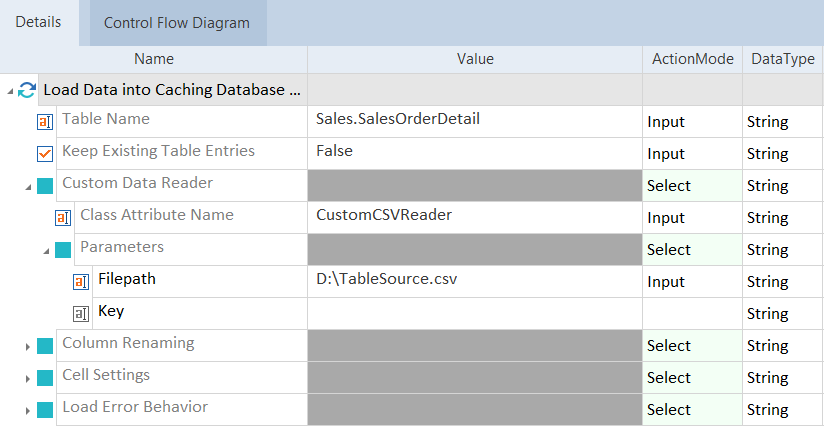
CSVファイルからキャッシュデータベースへのデータの読み込み
これでテストケースを実行できます。