Textdateien
Um verschiedene Tests für Textdateien zu erstellen, müssen Sie die folgenden Schritte ausführen:
-
Laden Sie Ihre Textdateien.
-
Führen Sie die Tests an den Textdateien aus. Nach dem Test lädt Tosca die Textdateien in eine SQLite-Datenbank.
-
Um zu verhindern, dass falsche Daten geladen werden, sollten Sie Pre-Screening-Tests an Ihren Textdateien durchführen.
Dazu können Sie die folgenden Module verwenden, die in der Untermenge Tosca Data Integrity Modules And Samples.tsu enthalten sind und sich im Ordner Modules->Data Integrity Testing befinden:
-
File Load into Caching Database
-
Defined File Tests against Caching Database
-
Complete Row by Row Comparison
-
Metadata Comparison
-
JSON/XML File Load into Caching Database
Voraussetzungen
Wenn Sie mit CSV-Dateien arbeiten, verwenden Sie das in RFC 4180 empfohlene Format. Dadurch wird sichergestellt, dass Tricentis Data Integrity die Dateien ordnungsgemäß verarbeiten kann.
File Load into Caching database
Verwenden Sie das Modul File Load into Caching Database, um den Inhalt einer Textdatei in eine SQLite-Datenbank zu laden. Mit diesem Modul können Sie mehrere Dateien laden.
Stellen Sie sicher, dass Sie den Pfad der SQLite-Caching-Datenbank im Dialog Einstellungen im Tosca Commander konfigurieren (siehe Kapitel "Einstellungen - Tricentis Data Integrity").

|
In diesem Beispiel laden Sie die Datei SalesLT.Address.SemiColon.txt in die Tabelle Address. Die Spalten der Datei sind durch Strichpunkte getrennt. Die erste Zeile enthält die Header-Namen.
Zeichenseparierte Datei laden |
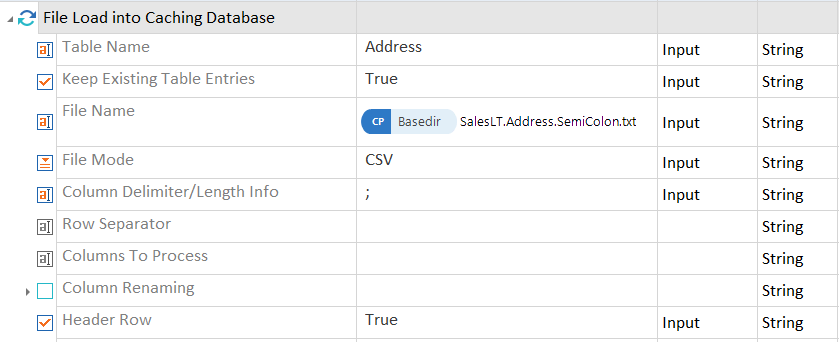
Das Modul File Load into Caching Database enthält die folgenden Attribute:
|
Modulattribut |
Beschreibung |
Optional |
|---|---|---|
|
Table Name |
Geben Sie den Namen der SQLite-Tabelle ein, in die Data Integrity die Daten lädt. |
|
|
Keep Existing Table Entries |
Setzen Sie den Wert auf True, um die Daten aus der Textdatei zur bestehenden Tabelle hinzuzufügen. Andernfalls verwirft Data Integrity die Tabelle vor dem Laden neuer Daten. |
X |
|
File Name |
Geben Sie den vollständigen Dateipfad und den Dateinamen der zu ladenden Textdatei ein. Sie können mehrere Dateien aus dem gleichen Verzeichnis in die gleiche Tabelle laden. Sie können bei Bedarf Platzhalter verwenden. Sie könnten z. B. C:\temp\myExcelFile*.csv eingeben. |
|
|
File Mode |
Definieren Sie, ob die Spalten eine feste Länge haben oder durch Kommas getrennt sind. |
|
|
File Encoding |
Wählen Sie das Dateicodierungsformat: Default, ASCII, Unicode oder UTF8. Default verwendet die Codierung Ihres Betriebssystems. |
X |
|
Column Delimiter/Length Info |
Geben Sie den Startpunkt für jede Spalte in einer durch Komma getrennten Liste oder das Trennzeichen in zeichenseparierten Dateien an. |
|
|
Row Separator |
Geben Sie das Zeichen an, das eine neue Zeile kennzeichnet. Verwenden Sie entweder Windows \r\n oder Unix \n. Der Standardwert ist \r\n oder \n. |
X |
|
Columns To Process |
Geben Sie eine durch Semikolon getrennte Liste von Spalten an, die geladen werden sollen. Standardmäßig lädt Data Integrity alle Spalten. |
X |
|
Column Renaming |
Benennen Sie Spalten per Datei um. Geben Sie den vollständigen Dateipfad zu einer Text- oder CSV-Datei mit den Spaltenzuordnungen an. Die Datei muss mit der Kopfzeile Aktueller Spaltenname;Zugeordneter Spaltenname, gefolgt von einer Zeile für jede Spalte, die Sie umbenennen möchten, beginnen. Beispiel: Aktueller Spaltenname;Zugeordneter Spaltenname Name1;Vorname Name2;Nachname |
X |
|
Column Renaming - <Current Name> |
Benennen Sie Spalten manuell um. Geben Sie in der Spalte Name den Namen der Spalte an, die Sie umbenennen möchten. Geben Sie in der Spalte Value den neuen Namen an. |
X |
|
Header Row |
Setzen Sie den Wert auf True, um anzugeben, ob die Datei eine Kopfzeile hat. Standardmäßig gibt es keine Kopfzeile. Falls sich die Kopfzeile in einer anderen Zeile befindet, geben Sie die Zeilennummer mit #<n> anstelle von True an. Es werden nur einzeilige Header unterstützt. |
X |
|
Skip Lines Starting With |
Geben Sie eine durch Semikolon getrennte Liste von Werten an, die übersprungen werden sollen. |
X |
|
Only Lines Starting With |
Definieren Sie eine durch Semikolon getrennte Liste von Zeichen, die eine gültige Zeile anzeigen. Zum Beispiel werden Prozesszeilen, die mit _, - oder < beginnen als _;-;< angegeben |
X |
|
Cell Settings - All Columns - Option |
Wenden Sie eine der unten beschriebenen Aktionen auf alle Spalten an. |
X |
|
Cell Settings - Single Columns - <Name> |
Wenden Sie eine der unten beschriebenen Aktionen auf eine bestimmte Spalte an. Um eine Spalte anzugeben, ersetzen Sie <Name> durch den Spaltennamen. |
X |
|
Load Error Behavior - Ignore Load Errors |
Definieren Sie, ob Ladefehler ignoriert werden. Der Standardwert ist False. |
X |
|
Load Error Behavior - Max Errors |
Definieren Sie die maximale Anzahl von Fehlern, bevor Tosca die Ausführung abbricht. Der Standardwert ist 100. |
X |
|
Load Error Behavior - File Name |
Geben Sie die Datei an, in der Fehler protokolliert werden. Geben Sie einen vollständigen Pfad und Dateinamen ein. Data Integrity überschreibt eine gegebenenfalls vorhandene Datei mit dem gleichen Namen. Standardmäßig protokolliert Data Integrity keine Ladefehler. |
X |
Aktionen für die Cell Settings
Sie können die folgenden Aktionen Cell Settings - All Columns und Cell Settings - Single Columns verwenden:
|
Aktion |
Beschreibung |
|---|---|
|
Trim |
Entfernen Sie alle führenden und abschließenden Leerzeichen. Standardeinstellung: HeaderAndData |
|
Trim[<character>] |
Entfernen Sie alle führenden und abschließenden Vorkommen des angegebenen Zeichens. Standardeinstellung: HeaderAndData Ersetzen Sie <character> durch das zu entfernende Zeichen. Zum Beispiel: Um das Zeichen " zu entfernen, geben Sie das Zeichen " viermal ein: Trim[""""]. |
|
TrimStart |
Entfernen Sie alle führenden Leerzeichen. Standardeinstellung: HeaderAndData |
|
TrimStart[<character>] |
Entfernen Sie alle führenden Vorkommen des angegebenen Zeichens. Standardeinstellung: HeaderAndData Ersetzen Sie <character> durch das zu entfernende Zeichen. Zum Beispiel: Um das Zeichen " zu entfernen, geben Sie das Zeichen " viermal ein: Trim[""""]. |
|
TrimEnd |
Entfernen Sie alle abschließenden Leerzeichen. Standardeinstellung: HeaderAndData |
|
TrimEnd[<character>] |
Entfernen Sie alle abschließenden Vorkommen des angegebenen Zeichens. Standardeinstellung: HeaderAndData Ersetzen Sie <character> durch das zu entfernende Zeichen. Zum Beispiel: Um das Zeichen " zu entfernen, geben Sie das Zeichen " viermal ein: Trim[""""]. |
|
Replace[<search string>][<replace string>] |
Ersetzen Sie alle Vorkommen der ersten durch die zweite Zeichenfolge. Standardeinstellung: Data |
|
Substring[<start index>] |
Extrahieren Sie einen Teil einer längeren Zeichenfolge. Das Extrahieren beginnt an der definierten Position start index und wird bis zum Ende der Zeichenfolge ausgeführt. Standardeinstellung: Data Beispiel: Substring[9] mit Eingabe Project Manager gibt Manager zurück. |
|
Substring[<start index>][<length>] |
Extrahieren Sie einen Teil einer längeren Zeichenfolge. Das Extrahieren beginnt an der definierten Position start index und enthält die Anzahl der in length angegebenen Zeichen. Standardeinstellung: Data Beispiel: Substring[9][3] mit Eingabe Project Manager gibt Man zurück. |
|
Right[<length>] |
Extrahieren Sie einen Teil einer längeren Zeichenfolge. Das Extrahieren wird vom Ende der Zeichenfolge in Richtung des Anfangs ausgeführt und enthält die Anzahl der in length angegebenen Zeichen. Standardeinstellung: Data Beispiel: Right[7] mit Eingabe Project Manager gibt Manager zurück. |
|
Lowercase |
Konvertieren Sie die Zeichenfolge unter Verwendung des aktuell aktiven Gebietsschemas in Kleinbuchstaben. Standardeinstellung: Data Beispiel: Lowercase mit Engabe Project Manager gibt project manager zurück. |
|
Lowercase[Culture:<culture name>] |
Konvertieren Sie die gesamte Zeichenfolge in Kleinbuchstaben. Lowercase[Culture:<culture name>] verwendet den gegebenen Kulturnamen, um ein neues Gebietsschema zu erstellen. Standardeinstellung: Data Beispiel: Lowercase[Culture:zh-Hans] verwendet die Kulturinformationen von "Chinese(simplified)", um die Groß- in Kleinbuchstaben zu konvertieren. |
| Uppercase |
Konvertieren Sie die Zeichenfolge unter Verwendung des aktuell aktiven Gebietsschemas in Großbuchstaben. Standardeinstellung: Data Beispiel: Uppercase mit Eingabe Project Manager gibt PROJECT MANAGER zurück. |
|
Uppercase[Culture:<culture name>] |
Konvertieren Sie die gesamte Zeichenfolge in Großbuchstaben. Uppercase[Culture:<culture name>] verwendet den gegebenen Kulturnamen, um ein neues Gebietsschema zu erstellen. Standardeinstellung: Data Beispiel: Lowercase[Culture:en-us] verwendet die Kulturinformationen von "English - United States", um die Klein- in Großbuchstaben zu konvertieren. |
Um die Standardeinstellung einer Aktion zu ändern, können Sie einen Parameter Scope hinzufügen:
-
Um die Aktion nur auf die Kopfzeile anzuwenden, fügen Sie den Parameter [Scope:Header] hinzu.
-
Um die Aktion auf alle Datenzeilen, jedoch nicht auf die Kopfzeile anzuwenden, fügen Sie den Parameter [Scope:Data] hinzu.
-
Um die Aktion auf die Kopfzeile und alle Datenzeilen anzuwenden, fügen Sie den Parameter [Scope:HeaderAndData] hinzu.
|
|
In diesem Beispiel wollen Sie alle Instanzen der Zeichenfolge CustomerDataAustria durch die Zeichenfolge CustomerDataUSA ersetzen. Sie möchten diese Änderung auf die Kopfzeile und alle Datenzeilen anwenden. Dazu definieren Sie die folgende Aktion: Replace[<CustomerDataAustria>][<CustomerDataUSA>][Scope:HeaderAndData] |
Das in Ihren Tests zu verwendende Modul angeben
Wenn Ihr Arbeitsbereich mehr als ein File Load into Caching Database-Modul enthält, müssen Sie angeben, welches Modul für Ihre Tests verwendet werden soll. Andernfalls wird das erste gefundene Modul verwendet.
Dies gilt auch, wenn die File Load into Caching Database-Module unterschiedliche Namen haben. Tosca DI verwendet nicht den Namen, um nach zutreffenden Modulen zu suchen, sondern den Konfigurationsparameter SpecialExecutionTask.
Um das zu verwendende Modul anzugeben, müssen Sie einen Konfigurationsparameter dafür anlegen. Führen Sie hierzu die folgenden Schritte aus:
-
Klicken Sie mit der rechten Maustaste auf das Modul und wählen Sie Create Configuration Param aus der Minisymbolleiste.
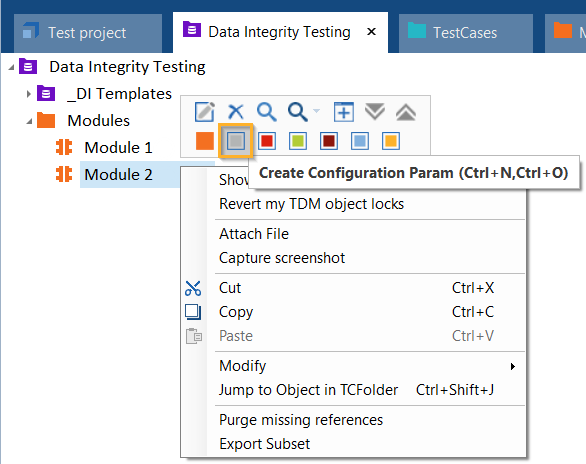
Erstellen Sie einen Konfigurationsparameter über die Minisymbolleiste.
-
Benennen Sie den neuen Konfigurationsparameter DIWizardUseInAutocreate.
-
Geben Sie unter Value den Wert True an.
Um Module zwischen den Tests zu wechseln, löschen Sie den Konfigurationsparameter aus einem Modul und fügen Sie ihn einem anderen Modul hinzu.
Stellen Sie sicher, dass nur bei jeweils einem File Load into Caching Database-Modul der Wert des Parameters DIWizardUseInAutocreate auf True gesetzt ist. Andernfalls verwendet Data Integrity das erste gefundene Modul.
Defined File Tests against Caching Database
Mit dem Modul Defined File Tests against Caching Database können Sie vordefinierte Tests auf Tabellen durchführen, die mit dem Modul File Load into Caching Database erstellt wurden.
Die folgende Tabelle zeigt die Testtypen im Wizard und dem entsprechenden Test im Modul:
|
Wizard-Testtyp |
Modul-Test |
|---|---|
|
Has No Empty Values |
NoEmptyValue |
|
Field Type |
IsNumeric |
|
Min Value |
MinValue |
|
Max Value |
MaxValue |
|
Sum |
Sum |
|
Value Range |
ValueRange |
|
Min Length |
MinLength |
|
Max Length |
MaxLength |
|
Exact Length |
Length |
|
Is Unique |
IsUnique |
|
Row Count |
RowCount |
Darüber hinaus sind die folgenden Tests nur im Modul verfügbar:
-
GreaterThan
-
GreaterThanOrEqualsTo
-
LessThan
-
LessThanOrEqualsTo
-
Between
-
BetweenOrEquals
-
Occurance
-
DoesColumnNameExist
Das Modul Defined File Tests against Caching Database enthält die folgenden Attribute:
|
Modulattribut |
Beschreibung |
|---|---|
|
Table Name |
Geben Sie den Namen der Tabelle an, die Sie testen möchten. |
|
Column |
Geben Sie den Namen der Spalte an, die Sie analysieren möchten. Data Integrity testet alle Zeilen innerhalb dieser Spalte. |
|
Test |
Geben Sie an, welchen Test Sie verwenden möchten. |
|
Param |
Verwenden Sie diesen Parameter, wenn der Testtyp eine zusätzliche Eingabe benötigt. Beispiel: Geben Sie für einen RowCount-Test die Nummer für die erwartete Anzahl von Zeilen ein. |
|
Value |
Überprüfen Sie das Gesamtergebnis. Wenn der Test erfolgreich war, erscheint die Meldung OK. Dieses Modulattribut erfordert die Aktion Verify. |
|
|
In diesem Beispiel überprüft Data Integrity die Zeilenanzahl einer Spalte. Die Spalte AddressID in der Tabelle Address enthält 450 Zeilen.
Zeilenanzahl überprüfen |
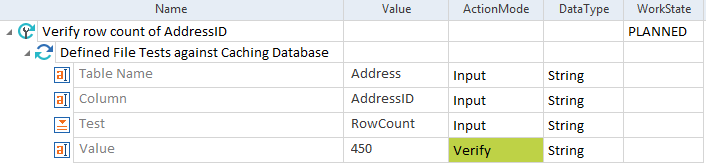
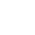
|
Weitere Beispiele finden Sie in der Untermenge Tosca Data Integrity Modules And Samples.tsu. Die Beispiele befinden sich im Ordner Sample tests->Sorted by use case->Pre Screening Tests->Against files. |